实验:Unet道路分割
2024-10-22 14:52:45
实验:Unet道路分割
Unet网络模型介绍:
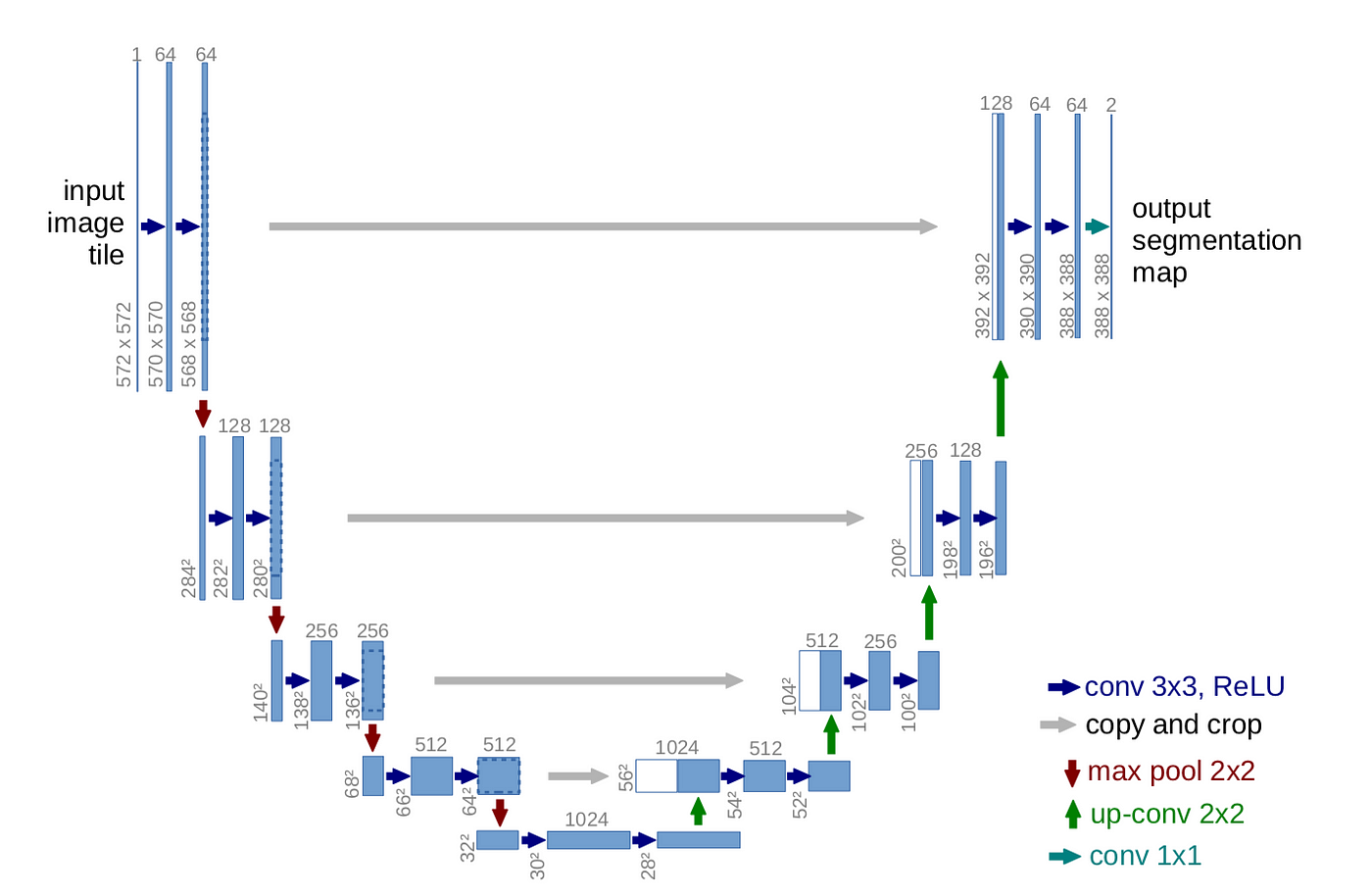
Unet(U-Net)是一种用于图像分割任务的深度学习模型架构,它在医学图像分割等领域广泛应用。这个架构的名称“U-Net”是因为它的网络结构外观类似字母“U”。
U-Net 最初是为了解决生物医学图像分割问题而提出的,尤其是对细胞图像进行精确分割。它的独特之处在于它将卷积神经网络(CNN)的编码器(捕捉图像特征)和解码器(生成分割结果)结合在一起,形成了一个对称的结构。这种结构使 U-Net 在保留图像上下文信息的同时,能够准确地捕捉不同尺度的特征。
U-Net 的主要组成部分包括:
- 编码器(Encoder):编码器部分通常由一系列的卷积层和池化层组成,用来逐步提取图像中的特征。这些特征在不同的层级上表示不同的抽象程度,从低级特征(如边缘)到高级特征(如纹理和形状)。
- 跳跃连接(Skip Connections):这是 U-Net 的一个关键特点。在编码器的每一层之后,会添加一个连接,将相应分辨率的特征图与解码器的对应层连接起来。这样做有助于传递更详细的信息给解码器,帮助它更好地还原细节。
- 解码器(Decoder):解码器部分也由一系列的卷积层和上采样(反池化)层组成,用来将编码器提取的特征重新映射到原始图像尺寸,并生成分割结果。跳跃连接帮助解码器在生成分割时融合不同层级的信息。
- 最后的卷积层:解码器的最后一层使用卷积层来生成最终的分割图像,通常使用适当的激活函数(如 sigmoid 或 softmax)来产生像素级的预测。
数据集划分
将数据集分为训练集、验证集和测试集是在机器学习和深度学习中常见的做法,其主要目的是评估模型的性能并进行泛化能力的估计。这种分割有助于模型的开发和优化过程,以及避免过拟合(在训练数据上表现良好,但在新数据上表现糟糕)的问题。
以下是每个集合的主要目的:
- 训练集(Training Set): 训练集是模型用来学习和调整参数的数据集。模型在训练集上进行多轮迭代,逐渐调整自己的权重和偏差,以最小化损失函数。模型在训练集上的表现会逐步提升,但这并不一定代表它在未见过的数据上也会表现良好。
- 验证集(Validation Set): 验证集用于调整模型的超参数(如学习率、正则化参数等),以优化模型的性能。在训练过程中,通过在验证集上进行评估,可以监控模型在未见过数据上的表现。如果模型在训练集上表现得很好,但在验证集上表现较差,可能出现了过拟合的情况。根据验证集的表现,可以进行超参数的调整,以达到更好的泛化性能。
- 测试集(Test Set): 测试集是用来评估模型在真实世界数据上的性能的数据集。测试集是模型完全没有见过的数据,用于最终评估模型的泛化能力。测试集的结果可以提供关于模型在真实情况下的性能指标,帮助判断模型是否足够好,是否适合部署到实际应用中。
通过将数据集分为训练集、验证集和测试集,可以更好地监控模型的表现、避免过拟合,并获得关于模型泛化性能的可靠估计。分割数据集还有助于在模型的开发过程中进行迭代和改进,以构建更准确、鲁棒的机器学习模型。
换个说法就是:
当我们训练一个模型时,为了确保它在不同情况下都能表现得好,我们通常把数据分成三份:训练集、验证集和测试集。这就好像是在学习时分成练习、考试前复习和最终考试三个阶段。
- 训练集:就像练习题一样,模型通过在训练集上学习,逐渐调整自己的能力。它会试着找到规律,让自己在练习上做得越来越好。
- 验证集:想象一下在考试前的复习。我们用验证集来调整模型的“策略”,比如要不要在解题中使用哪些方法,或者要不要调整学习的速度。这样,我们可以更好地准备模型应对真正的考试,也就是测试集。
- 测试集:就是最终考试。测试集包含了模型完全没有见过的问题,这样我们就可以看看模型在真实情况下的表现如何。这个阶段能告诉我们模型是否真的学得很好,能不能应对新的问题。
所以,分成这三部分有助于我们监控模型的学习过程,防止它只是死记硬背了训练集上的题目。同时,它也能让我们调整模型,确保它在各种情况下都能有好的表现。最后,通过测试集,我们能判断模型是否准备好面对真实世界中的挑战。
道路分割实验:
1、数据处理
1 | import os |
2、抽样检查
1 | import numpy as np |
3、构建Unet模型网络-编码器
1 | import paddle |
4、构建Unet模型网络-解码器
1 | import paddle |
6、构建Unet模型网络
1 | import paddle |
7、训练集读取器
1 | from paddle.io import Dataset |
9、训练
1 | import paddle |
10、推理
1 | from Library.RoadDataset import RoadDataset |
11、推理结果可视化
1 | import matplotlib.pyplot as plt |
12、模型评估(参考)
1 | __all__ = ['SegmentationMetric'] |