实验:手写数字识别(全连接神经网络)
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别等领域,大大缩短了业务处理时间,提升了工作效率和质量。
在处理如 图 1 所示的手写邮政编码的简单图像分类任务时,可以使用基于 MNIST 数据集的手写数字识别模型。MNIST 是深度学习领域标准、易用的成熟数据集,包含 50 000 条训练样本和 10 000 条测试样本。

- 任务输入:一系列手写数字图片,其中每张图片都是 28x28 的单通道像素矩阵。
- 任务输出:经过了大小归一化和居中处理,输出对应的 0~9 的数字标签。
手写数字识别的模型是深度学习中相对简单的模型,非常适用初学者。正如学习编程时,我们输入的第一个程序是打印“Hello World!”一样。 在飞桨的入门教程中,我们选取了手写数字识别模型作为启蒙教材,以便更好的帮助读者快速掌握飞桨平台的使用。
1)数据简介
飞桨提供了多个封装好的数据集 API,涵盖计算机视觉、自然语言处理、推荐系统等多个领域,帮助读者快速完成深度学习任务。如在手写数字识别任务中,通过paddle.vision.datasets.MNIST可以直接获取处理好的 MNIST 训练集、测试集。
MNIST 是一个经典的手写数字数据集,广泛用于测试和验证机器学习和深度学习模型的性能。它是深度学习领域中最常见的基准数据集之一。
MNIST 数据集包含了大量的手写数字图像,每个图像都是单个 0 到 9 之间的数字。图像的尺寸固定为 28x28 像素,通常以灰度图像的形式呈现。这意味着每个图像都由一个二维数组表示,数组中的每个元素代表图像上对应位置的像素值。
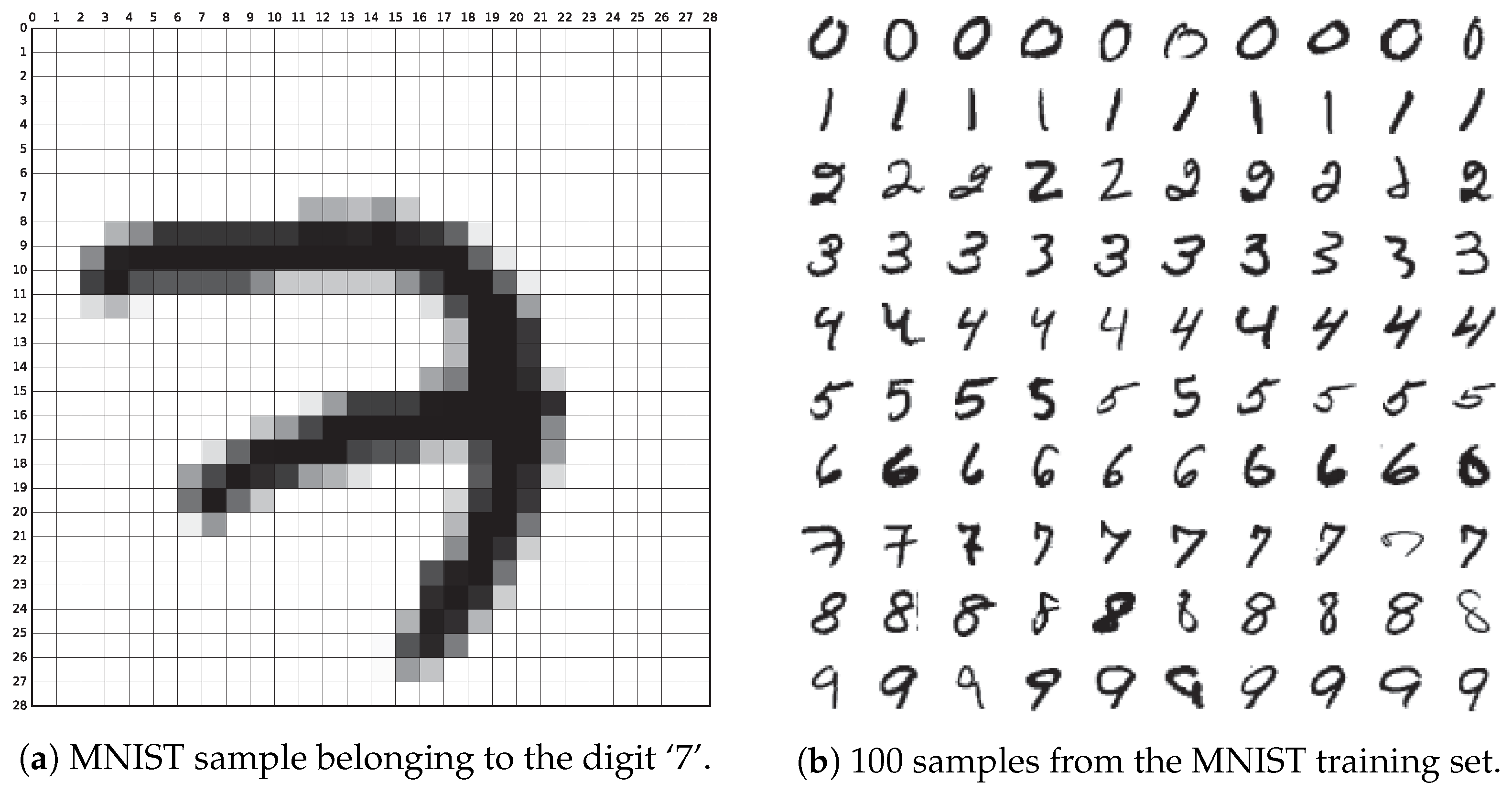
MNIST 数据集总共包含 60000 个训练样本和 10000 个测试样本。训练集用于训练模型,测试集用于评估模型在未见过数据上的性能。这个数据集的标签已经预先确定,因此我们知道每个图像对应的真实数字标签。
MNIST 数据集在计算机视觉和深度学习社区中被广泛使用,特别是在图像分类任务中。许多研究论文和教程都使用 MNIST 数据集来演示和比较不同的算法和模型,因为它的相对简单性和可用性使得许多人都能轻松地开始尝试机器学习和深度学习技术。

2)查看数据集中图片和标签
1
2
3
4
| import paddle
train_dataset = paddle.vision.datasets.MNIST(mode='train')
|
通过如下代码读取任意一个数据内容,观察打印结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import numpy as np
train_data0 = np.array(train_dataset[0][0])
train_label_0 = np.array(train_dataset[0][1])
import matplotlib.pyplot as plt
plt.figure("Image")
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
plt.axis('on')
plt.title('image')
plt.show()
print("图像数据形状和对应数据为:", train_data0.shape)
print("图像标签形状和对应数据为:", train_label_0.shape, train_label_0)
print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(train_label_0))
|
3)加载数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
| from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
|
4)构建网络
1
2
3
4
5
6
7
8
9
| import paddle
from paddle.vision.transforms import Normalize
mynet = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 10),
paddle.nn.Softmax()
)
|
5)定义模型、优化器和损失函数
1
2
3
4
5
6
7
8
9
10
11
12
13
|
model = paddle.Model(mynet)
model.prepare(
optimizer = paddle.optimizer.Adam(
learning_rate = 0.001,
parameters = model.parameters()
),
loss = paddle.nn.CrossEntropyLoss(),
metrics = paddle.metric.Accuracy()
)
|
6)训练模型
1
2
3
4
5
6
|
model.fit(train_dataset,
val_dataset,
epochs=10,
batch_size=64,
verbose=1)
|
7)模型预测推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
test_data0 = np.array(val_dataset[0][0])
test_label_0 = np.array(val_dataset[0][1])
print(test_data0.shape)
test_data0 = test_data0.reshape(1,1,28,28)
predict_results = model.predict(test_data0)
for idx, pred in enumerate(predict_results[0]):
pred_label = np.argmax(pred)
print(f"样本 {idx} 的预测结果标签是: {pred_label}")
|
8)模型保存
1
2
3
4
|
model.save("digit_recognition_model")
model.load("digit_recognition_model")
|
9)加载模型进行推理
动态图推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import paddle
from paddle.vision.transforms import Normalize
import numpy as np
mynet = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 10),
paddle.nn.Softmax()
)
model = paddle.Model(mynet)
model.load("./digit_recognition_model")
model.prepare(
optimizer = paddle.optimizer.Adam(
learning_rate = 0.001,
parameters = model.parameters()
),
loss = paddle.nn.CrossEntropyLoss(),
metrics = paddle.metric.Accuracy()
)
"""
归一化处理
mean=[127.5]: 均值127.5
std: 标准方差为127.5
data_format: 数据模式: C:通道数, H:高度, W: 宽度
"""
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
test_data0 = np.array(val_dataset[0][0])
test_data0 = test_data0.reshape(1, 1, 28, 28)
predict_results = model.predict(test_data0)
pred = predict_results[0][0]
pred_label = np.argmax(pred)
print(f"预测结果标签是: {pred_label}")
|
静态图推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import paddle
import numpy as np
from paddle.vision.transforms import Normalize
import matplotlib.pyplot as plt
train_dataset = paddle.vision.datasets.MNIST(mode='train')
val_dataset = paddle.vision.datasets.MNIST(mode="test")
train_data0 = np.array(train_dataset[1][0])
train_data1 = np.array(train_dataset[1][1])
plt.figure(figsize=(2, 2))
plt.imshow(train_data0, cmap=plt.cm.binary)
plt.show()
|
加载数据集
1
2
3
4
5
6
7
| transfrom = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transfrom)
val_dataset = paddle.vision.datasets.MNIST(mode="test", transform=transfrom)
|
加载静态图模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import paddle
paddle.enable_static()
startup_prog = paddle.paddle.static.default_startup_program()
"""
❗❗❗❗❗❗❗❗❗
该路径是在保存模型的时候导出的路径
注意这里的training是False的时候,导出的是静态图。
model.save("mnist_cnn_model", training=False)
"""
path_prefix = './djdj/digit_recognition_model'
exe = paddle.static.Executor(paddle.CPUPlace())
exe.run(startup_prog)
[inference_program, feed_target_names, fetch_targets] = (
paddle.static.load_inference_model(path_prefix, exe))
rowitem = val_dataset[1]
tensor_img = rowitem[0][np.newaxis]
labels = rowitem[1]
results = exe.run(inference_program,
feed={feed_target_names[0]: tensor_img},
fetch_list=fetch_targets)
predicted = np.argmax(results, axis=-1)[0]
print(f"Predicted class: {predicted}, Real class: {labels}")
|