
百度飞桨的安装和基本操作
01|百度飞桨简介
飞桨(PaddlePaddle)是基于百度多年深度学习技术研究和业务应用的基础上,由百度自主研发的产业级深度学习平台。它是中国首个功能完备、开源开放的深度学习平台。飞桨集成了深度学习核心训练和推理框架、基础模型库、端到端开发套件以及各种工具组件。
关键统计数据:
- 累计开发者数量达到 535 万人。
- 服务的企业数量为 20 万家。
- 基于飞桨平台开发的深度学习模型数量达到 67 万个。
飞桨的主要特点和作用有:
- 帮助开发者快速实现人工智能(AI)的想法。
- 加速 AI 业务的上线和部署。
- 在各个行业中推动人工智能赋能,促进产业智能化升级。
02|百度飞桨安装
百度飞桨框架提供了适用于 CPU 和 GPU 两种不同的运行环境。下面将分别介绍在 CPU 环境和 GPU 环境下的安装方法。
A) 通用软件
Anaconda 是一个开源的 Python 和 R 编程语言的发行版本,用于科学计算、数据分析、人工智能开发等领域。它提供了一个集成的开发环境,包括了许多常用的科学计算库、工具和环境管理功能,使得安装、管理和切换不同版本的库和工具变得更加便捷。
Anaconda 主要有以下特点:
- 包含了许多常用的科学计算和数据分析库,如 NumPy、Pandas、Matplotlib 等。
- 提供了 Conda 包管理系统,可以用于安装、升级、删除软件包,管理环境等。
- 支持虚拟环境,可以创建独立的环境,使不同项目可以使用不同的库和版本,互相不受影响。
- 适用于多个操作系统,包括 Windows、macOS 和 Linux。
以下是安装 Anaconda 的基本步骤:
注意:在安装 Anaconda 之前,建议先卸载掉已经存在的 Python 发行版本,以避免冲突。
- 下载安装程序: 访问 Anaconda 官方网站(https://www.anaconda.com/products/distribution)下载适用于你操作系统的Anaconda安装程序。
- 选择版本: Anaconda 提供了两个版本:Anaconda 和 Miniconda。Anaconda 版本包含了大量的预安装库,而 Miniconda 只包含了最基本的内容。对于大多数用户来说,建议选择 Anaconda 版本,因为它已经包含了许多常用的库,减少了后续的安装工作。

- 运行安装程序: 下载完成后,运行下载的安装程序。按照安装程序的提示进行安装。在安装过程中,你可以选择安装路径、添加到系统环境变量等选项。
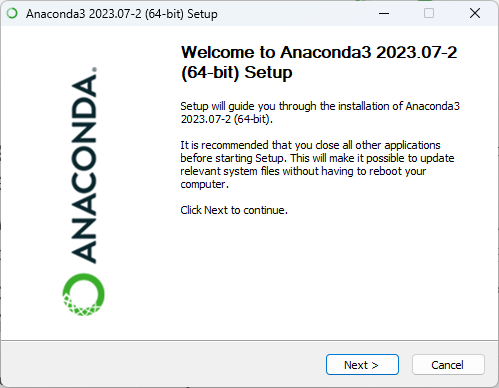
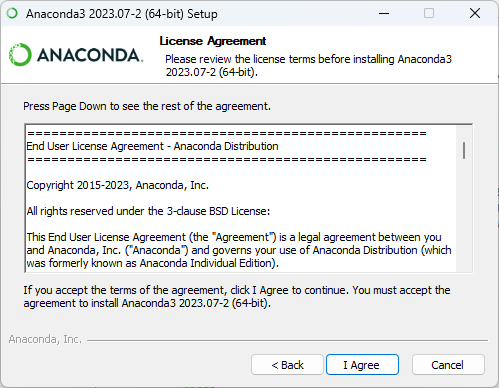
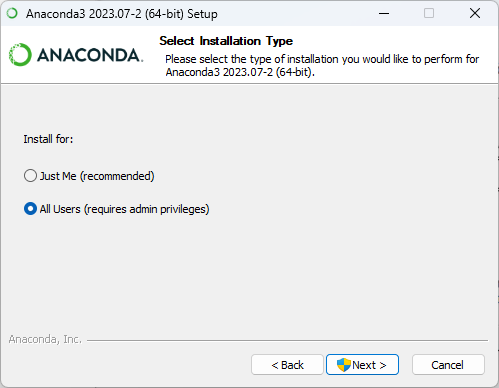
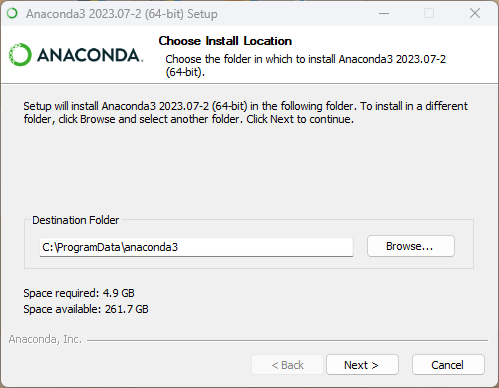

启动 Anaconda Navigator(可选): 安装完成后,你可以通过 Anaconda Navigator 来管理环境和库。Anaconda Navigator 提供了一个可视化界面,使得创建、管理虚拟环境和安装库变得更加直观。

使用 Conda: 安装完成后,你可以在命令行中使用 Conda 命令来管理环境和库。例如,可以使用以下命令创建一个新的虚拟环境:
1 | conda create -n myenv python=3.8 |
这会创建一个名为”myenv”的Python虚拟环境。
3、查看 Conda 环境:
1 | conda env list |
- 激活 Conda 环境:
1 | conda activate myenv |
B) CPU 环境安装
在 CPU 环境下安装百度飞桨框架非常简单:
打开终端或命令提示符。
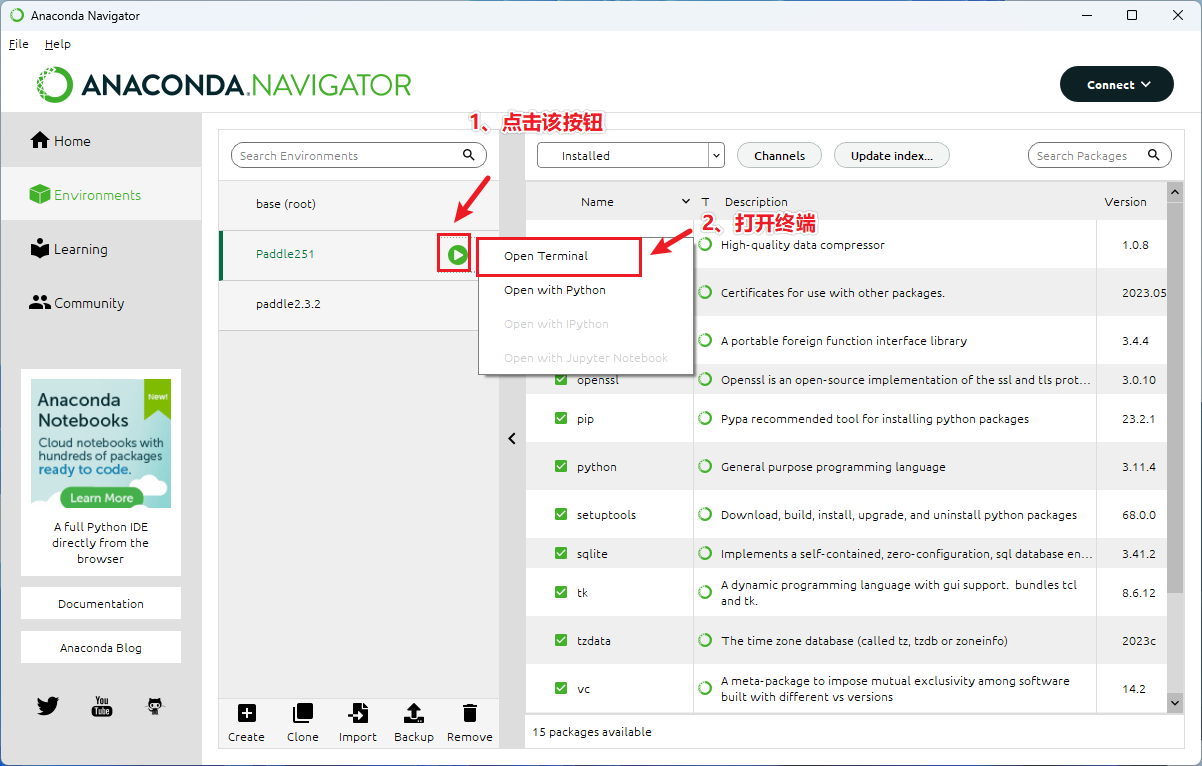
输入以下命令来安装飞桨框架:
1 | conda install paddlepaddle==2.5.1 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ |
- 等待安装完成,即可在 CPU 环境下使用百度飞桨框架。
C) GPU 环境安装
如果你想在 GPU 环境下使用飞桨框架,需要安装 Anaconda、CUDA 以及 cnnda 等工具。
若自行下载,一定要对应下图种的版本:

在此处本教程选择使用 cuda11.6、cudnn8.4.0.2

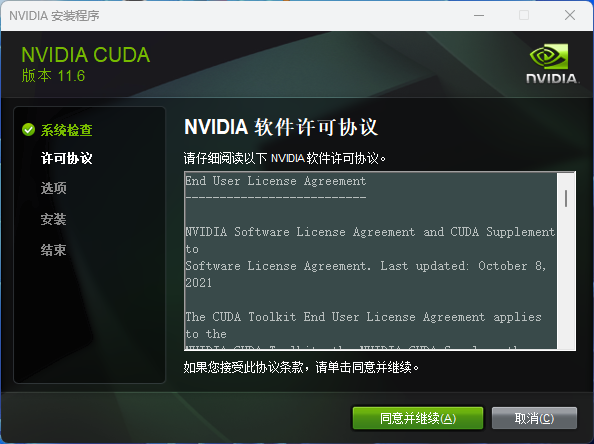
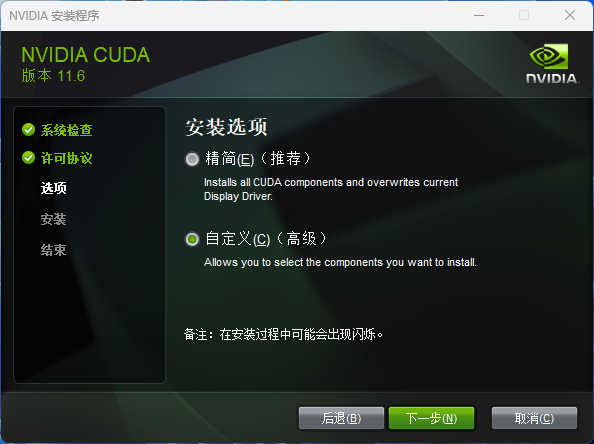
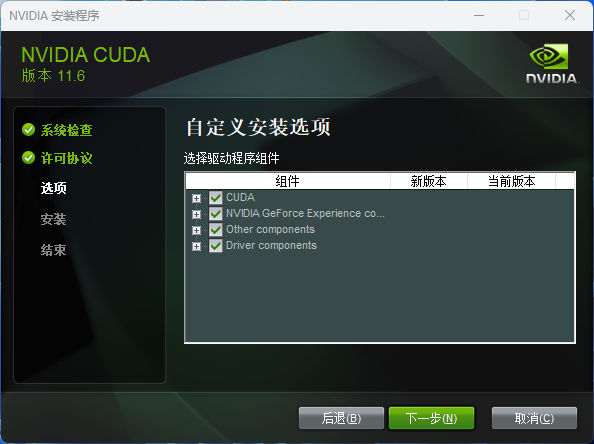
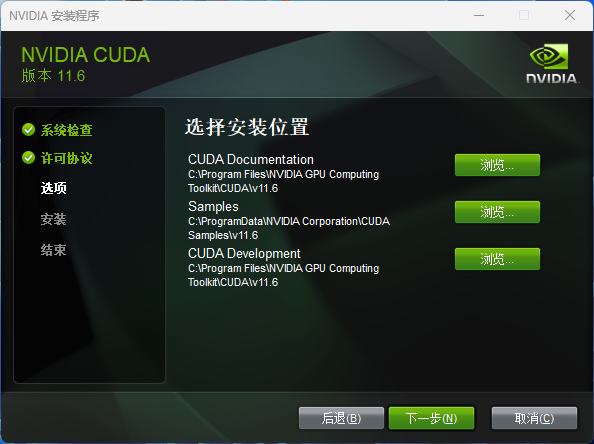
CUDA 安装过程
CUDA(Compute Unified Device Architecture)是由 NVIDIA 公司开发的一种并行计算平台和编程模型。CUDA 使开发人员能够在 NVIDIA 的 GPU(图形处理器)上进行通用计算,而不仅仅是用于图形渲染。通过 CUDA,开发人员可以利用 GPU 的并行处理能力来加速各种类型的计算任务,包括科学计算、数据分析、深度学习、图像处理等。
下载地址:https://developer.nvidia.com/cuda-downloads
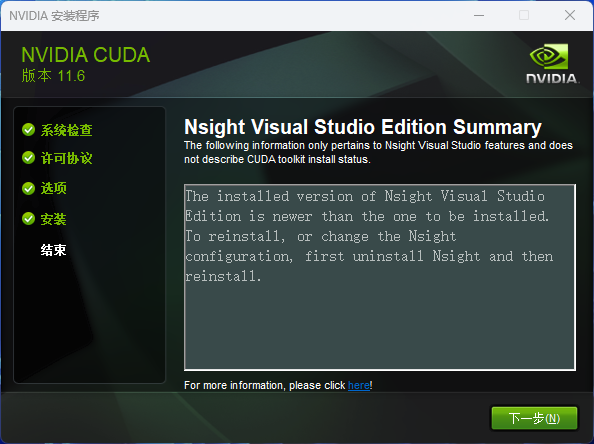
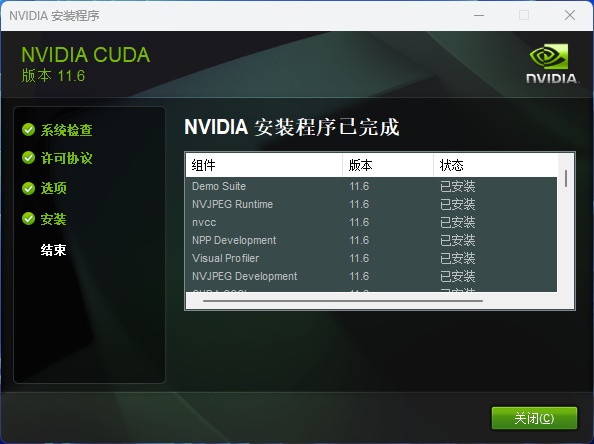
CuDNN 安装过程
CuDNN(CUDA Deep Neural Network),是 NVIDIA 为深度学习任务而开发的一个库。CuDNN 提供了一些高性能的基础操作和优化,如卷积、池化、正则化等,可以帮助深度学习框架更高效地运行在 NVIDIA 的 GPU 上。它通过针对深度学习任务的特定优化,加速了神经网络模型的训练和推断过程。
下载地址:https://developer.nvidia.com/cudnn
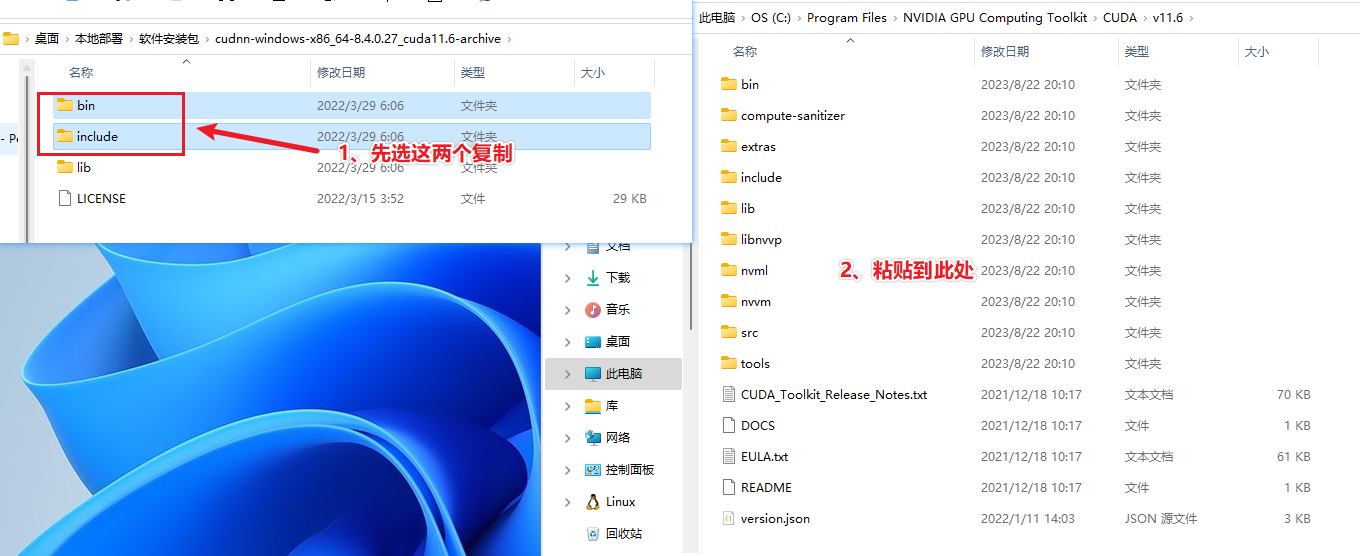
1、将cudnn-windows-x86_64-8.4.0.27_cuda11.6-archive文件夹中的bin、include,粘贴到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64里面。
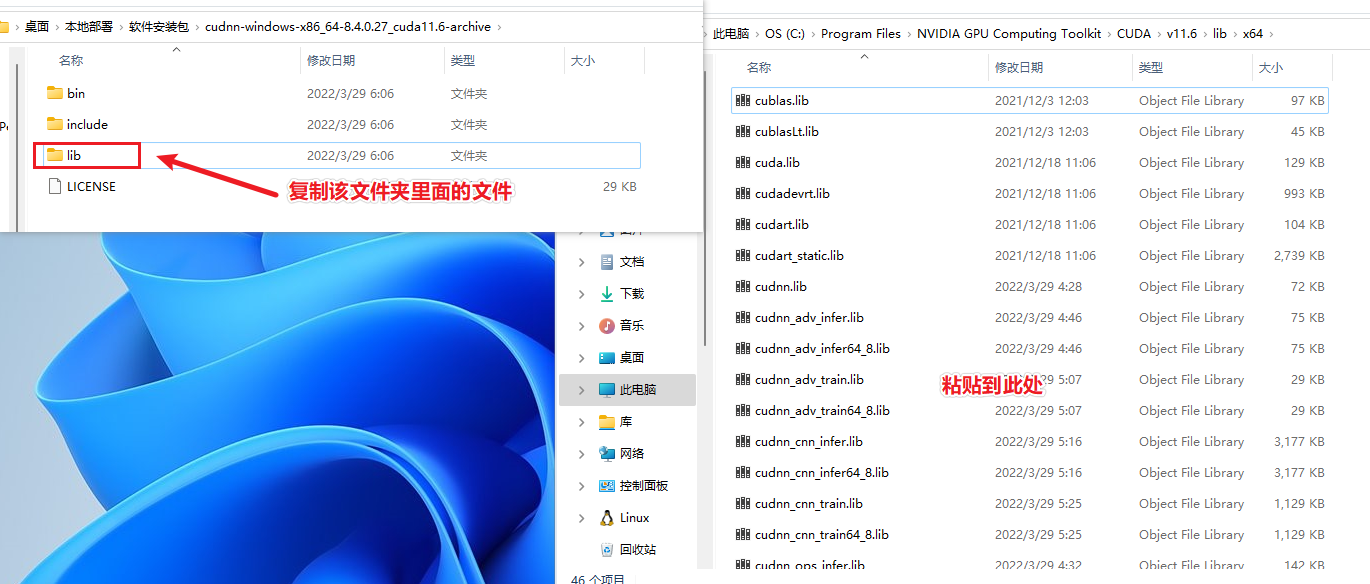
2、将将cudnn-windows-x86_64-8.4.0.27_cuda11.6-archive文件夹中的lib文件夹中的所有文件粘贴到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64里面。
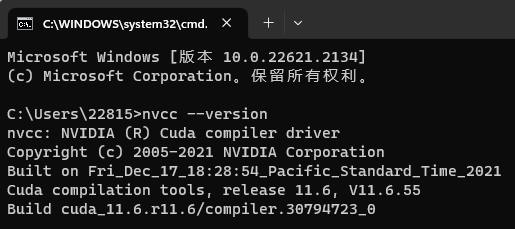
测试 CUDA 是否安装成功
组合键win+r输入 cmd,输入下方命令:
1 | nvcc --version |
出现对应的 cuda 版本即可认为安装成功。
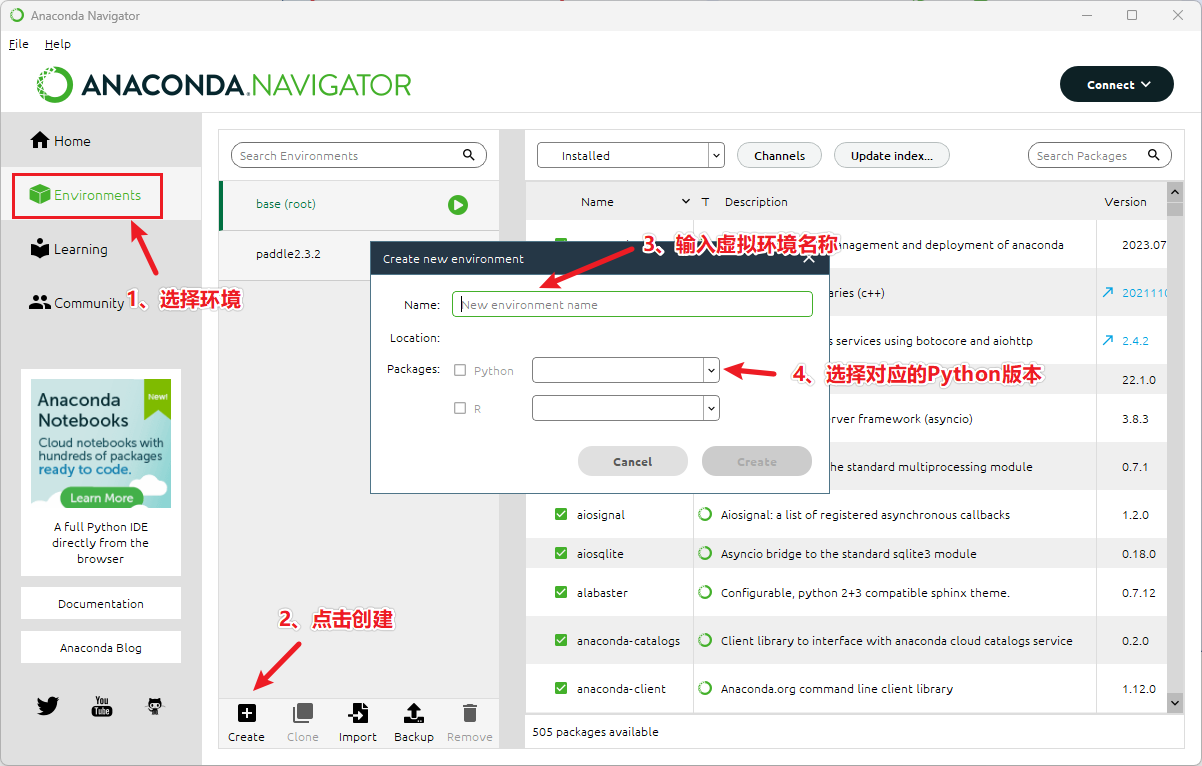
创建虚拟 Python 环境
按 win 键呼出开始,搜索 Anaconda Navigator
1、选择环境(Environments)
2、点击创建(Create)
3、输入虚拟环境名称
4、选择对应的 Python 版本
安装百度飞桨方式一:命令安装

在终端输入如下命令:
1 | conda config --set ssl_verify false |
1 | conda install paddlepaddle-gpu==2.5.1 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge |
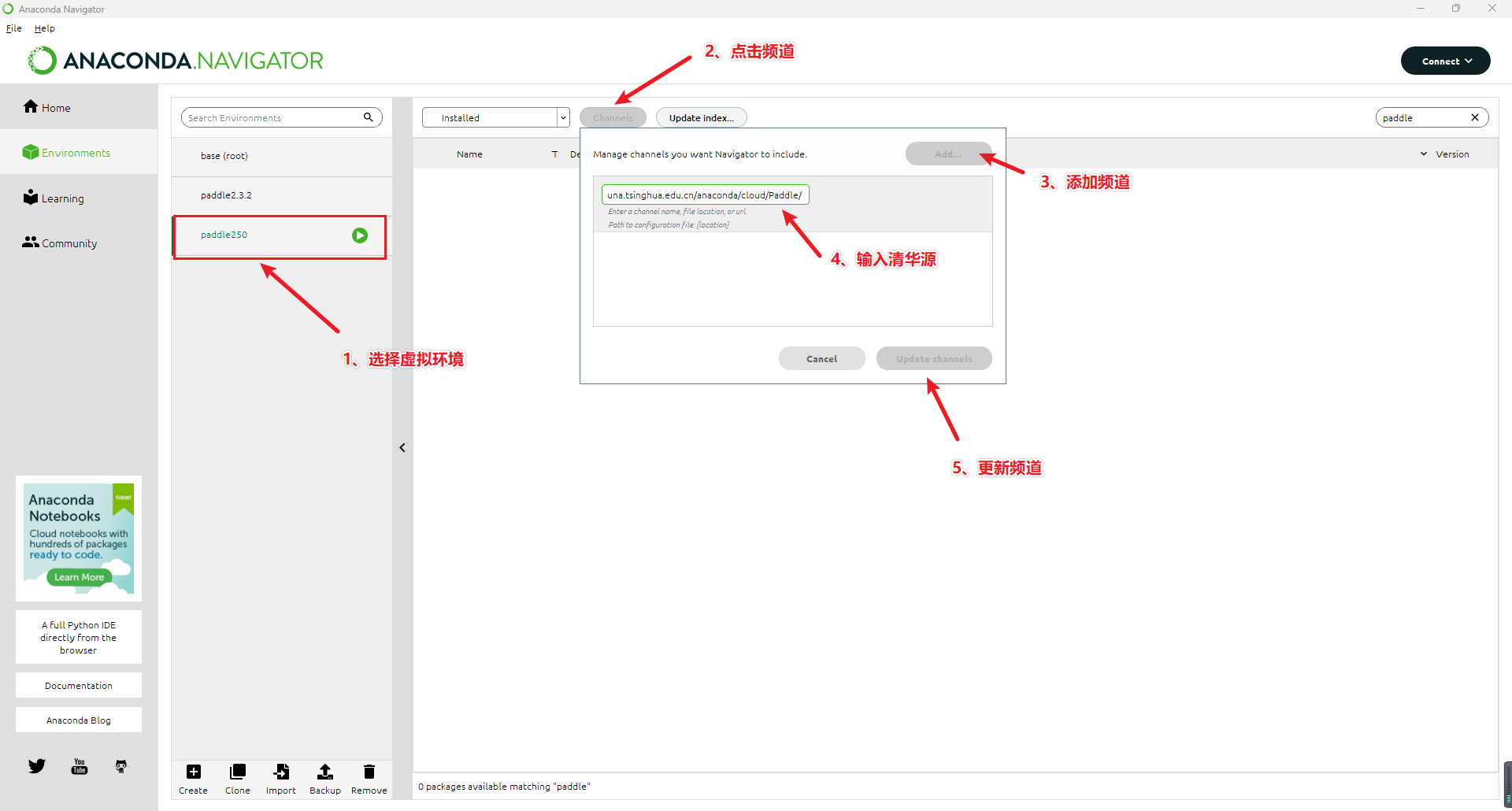
安装百度飞桨方式二:界面安装
换清华源
打开文件C:\Users\你的用户名\.condarc,并编辑内容:
1 | channels: |
1、选择虚拟环境
2、点击频道
3、添加频道
4、输入清华源
5、更新频道(清华源:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/)

D) 验证是否安装成功
打开 Python 环境:
在 Python 环境中输入:
1 | import paddle |
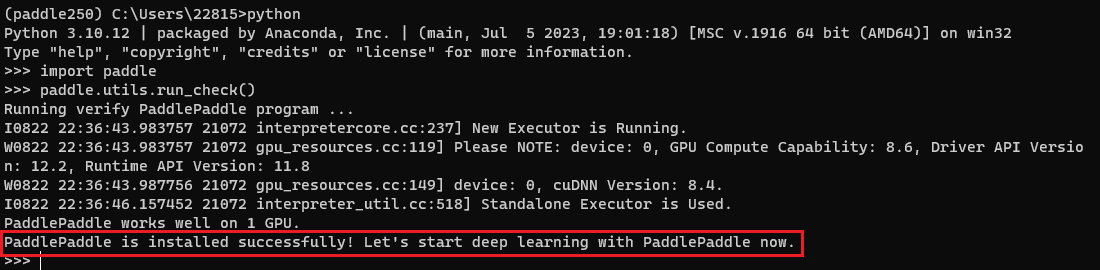
看到终端中输出如下字符串,则代表百度飞桨已经安装成功:
1 | Running verify PaddlePaddle program ... |
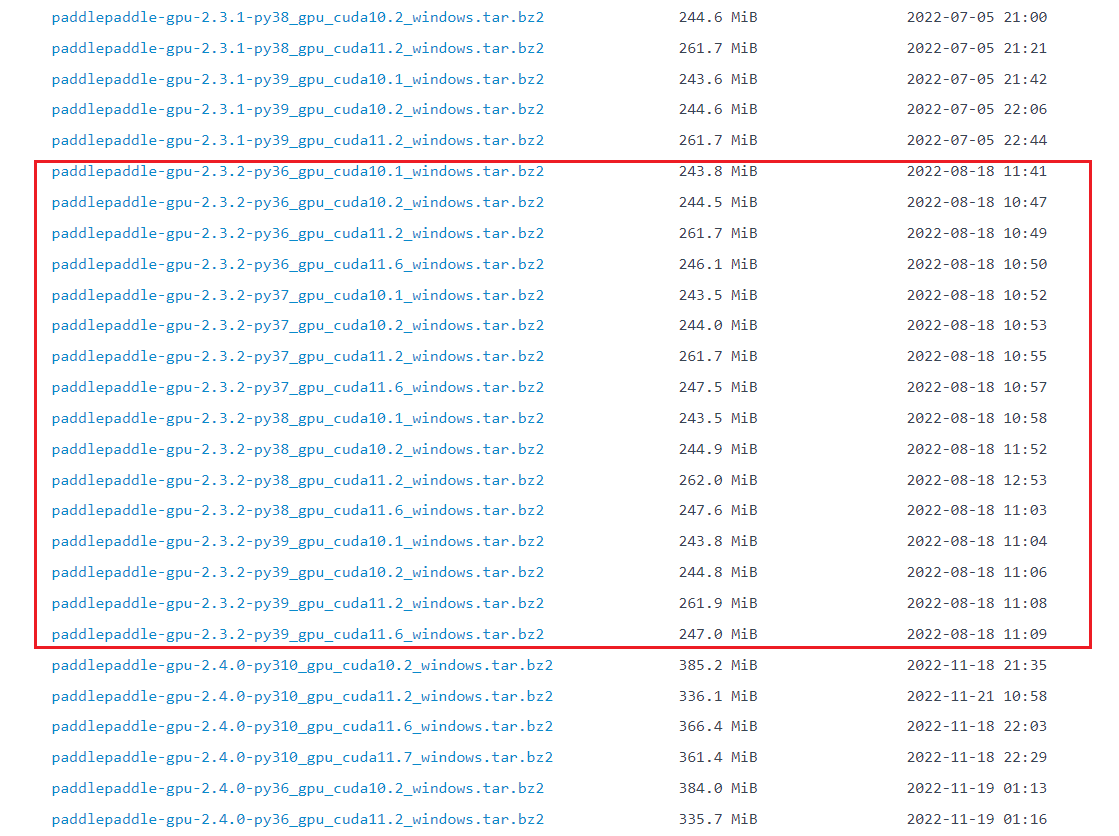
E)安装避坑
可以看到下图,paddlepaddle-gpu-2.3.2 版本在 python 3.10 以上的版本,是没有对应的安装包的。
百度飞桨中的张量
在神经网络处理的数据时,飞桨使用一种叫做“张量”的结构来表示。你可以将张量想象成是一种多维数组,类似于你在 Numpy 库中使用的数组(叫做 ndarray)。不过,与 Numpy 数组不同的是,张量不仅可以在普通的计算机 CPU 上运行,还可以在 GPU 和其他各种人工智能芯片上运行,以实现更快的计算速度。
除此之外,飞桨建立在张量的基础上,实现了深度学习中必需的反向传播功能,以及各种各样的网络操作功能。这使得你能够更方便地构建深度学习模型,并进行训练。如果你想了解张量和 Numpy 数组之间的具体差异,可以参考后面关于张量和 Numpy 数组相互转换的部分。
张量的创建
使用 NumPy 数组创建:
你可以使用 NumPy 数组创建一个张量。飞桨支持与 NumPy 紧密集成,所以你可以直接将 NumPy 数组转换成张量。
1 | import numpy as np |
你可以直接通过赋值来创建张量。
一维张量:
1 | import paddle |
二维张量:
1 | ndim_2_Tensor = paddle.to_tensor([[1.0, 2.0, 3.0], |
三维张量:
1 | ndim_3_Tensor = paddle.to_tensor([[[1, 2, 3, 4, 5], |
错误的例子:❌
请注意,张量的形状必须是类似于矩形的,也就是说,在张量的每一个维度上,元素的数量必须是一样的,不能不同。如果某个维度上的元素数量不同,那么就会产生错误。
1 | ndim_2_Tensor = paddle.to_tensor([[1.0, 2.0], |
指定形状创建
可以使用特定的值来初始化张量,例如全零或全一张量。
1 | paddle.zeros([m, n]) # 创建数据全为 0,形状为 [m, n] 的 Tensor |
指定区间创建
1 | paddle.arange(start, end, step) # 创建以步长 step 均匀分隔区间[start, end)的 Tensor |
例如:
1 | paddle.arange(start=1, end=5, step=1) # [1, 2, 3, 4] |
指定图像、文本数据创建
在各种深度学习任务中,会处理各种类型的数据样本,比如图片、文本、语音等。在将这些数据样本输入神经网络进行训练或推理之前,你需要将它们以及对应的标签转换成张量(Tensor)。下面我将介绍在图像和自然语言处理(NLP)场景中,如何手动进行这些张量转换的方法。
图像场景:
- 对于图像数据,你可以使用
paddle.vision.transforms.ToTensor来直接将图像从 PIL.Image 格式转换为张量(Tensor)。 - 图像的标签通常是 Python 列表或 NumPy 数组的形式,你可以使用
paddle.to_tensor来将这些标签转换为张量(Tensor)。
文本场景:
- 在处理文本数据时,首先需要将文本内容转换成数字表示。这个过程通常包括词汇表构建和将文本转换成对应的数字索引。
- 一旦文本被转换成数字,你可以使用
paddle.to_tensor将其转换为张量(Tensor)。 - 不同的文本任务可能会有不同形式的标签。有些任务的标签本身也是文本,而有些任务的标签则是数字。无论如何,最终你都需要使用
paddle.to_tensor将标签转换为张量(Tensor)。
无论是处理图像还是文本数据,在将其送入神经网络之前,你都需要进行相应的数据预处理,将数据和标签转换为张量(Tensor)的形式,以便神经网络能够处理它们。
1 | import numpy as np |
Tensor 属性
在 Tensor 中,形状(shape)是一个关键的属性,通过查看Tensor.shape,我们可以了解 Tensor 的形状。以下是相关概念的说明:
- 形状(shape): 形状描述了 Tensor 每个维度上元素的数量。它告诉我们 Tensor 在每个维度上有多少个元素。
- 维度数量(ndim): 维度数量表示 Tensor 的维度个数。例如,向量的维度为 1,矩阵的维度为 2,而 Tensor 可以有任意数量的维度。
- 轴或维度(axis/dimension): 轴或维度是 Tensor 的不同特定维度。我们可以通过指定轴来访问 Tensor 的特定维度上的数据。
- 元素个数(size): 元素个数指的是 Tensor 中的总元素数量,即 Tensor 的所有维度中元素的乘积。
为了更好地理解这些概念之间的关系,我们可以通过一个图形来表示:
1 | import paddle |
在这个例子中,ndim_4_Tensor是一个四维的 Tensor,它的形状为(2, 3, 4, 5)
- 维度数量(ndim)为 4,因为有四个维度。
- 形状(shape)为
(2, 3, 4, 5),表示每个维度上的元素数量。 - 轴或维度(axis/dimension)可以分别是 0、1、2、3,用来访问不同维度上的数据。
- 元素个数(size)为 2 _ 3 _ 4 * 5 = 120,因为总共有 120 个元素。
通过这个例子,我们可以更好地理解 Tensor 形状相关概念之间的关系。
调整张量的形状
在深度学习任务中,经常需要调整张量的形状(shape)以适应不同的计算需求。飞桨(PaddlePaddle)框架提供了 paddle.reshape 方法来实现这一目的。下面是您提供的代码示例的整理和解释:
1 | import paddle |
通过例子进一步说明:
1 | import paddle |
张量的数据类型
当处理张量(Tensor)时,其数据类型(dtype)是一个重要的属性,它决定了张量中存储的元素的数据类型。飞桨(PaddlePaddle)框架支持多种数据类型,包括 bool、float16、float32、float64、uint8、int8、int16、int32、int64、complex64 和 complex128。以下是有关张量数据类型的课件内容:
1. 张量的数据类型介绍:
- 数据类型决定了张量中存储的元素类型,影响了计算精度和存储空间。
- 飞桨支持多种数据类型,如 float32 用于浮点数、int64 用于整数等。
2. 创建张量时指定数据类型:
- 通过给定的 Python 序列创建张量时,可以使用
dtype参数指定数据类型。 - 如果不指定数据类型,Python 整型数据默认创建 int64 型张量,Python 浮点型数据默认创建 float32 型张量。
1 | import paddle |
3. 通过 Numpy 数组或其他张量创建张量:
- 当从 Numpy 数组或其他张量创建张量时,新张量的数据类型与原始数据保持一致。
4. 复数类型数据处理:
- 张量也支持复数类型数据。如果输入数据为复数,张量的数据类型可以是 complex64 或 complex128,每个元素为一个复数。
5. 改变张量数据类型:
- 使用
paddle.cast可以改变张量的数据类型。 - 可以将一个数据类型的张量转换为另一个数据类型。
1 | float32_tensor = paddle.to_tensor(1.0) |
张量索引和切片
索引和切片是在深度学习中对张量进行访问和修改的重要操作。飞桨框架与 Python 的索引规则和 Numpy 的索引规则类似。以下是关于索引和切片操作的整理和解释:
1. 索引和切片概述:
索引和切片操作允许访问或修改张量中的元素,基于以下规则:
- 使用从 0 到 n-1 的整数索引。负数索引从尾部开始计算。
- 使用冒号
:分隔切片参数,start:stop:step表示切片操作,其中start、stop、step可以缺省。
2. 一维张量的索引和切片:
对于一维张量,可以在单个维度上进行索引或切片操作。
1 | import paddle |
3. 多维张量的索引和切片:
对于二维及以上的张量,可以在多个维度上进行索引或切片操作。
1 | ndim_2_tensor = paddle.to_tensor([[0, 1, 2, 3], |
对于多维张量,索引或切片的每个值对应一个维度,未指定的维度默认为 :。例如,ndim_2_tensor[1] 相当于 ndim_2_tensor[1, :]。
飞桨的自动微分机制,优化器以及常见的模型训练和评估流程
飞桨(PaddlePaddle)是一个支持自动微分的深度学习框架,它提供了强大的工具来构建、训练和评估深度学习模型。下面是关于飞桨的自动微分机制、优化器以及常见的模型训练和评估流程的介绍:
自动微分机制: 飞桨具有自动微分功能,这是深度学习中的重要部分。自动微分允许你计算关于损失函数的梯度的模型参数,这对于优化模型参数以最小化损失函数非常关键。在飞桨中,你可以通过创建一个需要梯度的张量并执行前向传播和反向传播来自动计算梯度。这使得你能够更轻松地构建和训练复杂的神经网络模型。
优化器: 飞桨提供了多种优化器,用于更新模型参数以降低损失函数。一些常见的优化器包括随机梯度下降(SGD)、Adam、RMSProp (Root Mean Square Propagation)等。你可以选择适合你问题的优化器,并调整其超参数以获得更好的训练效果。
模型训练和评估流程: 通常,深度学习模型的训练和评估分为以下几个步骤:
- 数据准备: 首先,你需要准备训练数据和测试数据。这可能包括加载图像、文本或其他数据,并将其转换为张量的形式。
- 模型构建: 使用飞桨,你可以构建神经网络模型。你可以选择从现有的模型架构中选择,或者自定义你自己的模型。
- 定义损失函数: 在训练过程中,你需要定义一个损失函数,它衡量了模型预测与真实标签之间的差距。
- 选择优化器: 选择一个适合的优化器来更新模型参数以最小化损失函数。
- 训练循环: 在训练循环中,你将多次迭代地执行以下步骤:
- 前向传播:使用当前的模型参数对训练数据进行前向传播,计算预测结果。
- 计算损失:将预测结果与真实标签比较,计算损失函数值。
- 反向传播:通过自动微分,计算损失函数关于模型参数的梯度。
- 更新参数:使用优化器根据梯度信息更新模型参数。
- 评估模型(验证集): 在训练过程中,你可以定期使用测试数据评估模型的性能(准确率、精确率、召回率、F1 Score)。计算预测结果并与真实标签进行比较,以计算模型的准确率、损失等指标。
- 调参和验证: 根据模型在验证数据上的表现,你可以调整超参数、网络结构等,以进一步提升模型性能。
- 模型保存与部署: 在训练完成后,你可以保存训练好的模型,以便将来用于推理或部署到生产环境(ARM)中。