优化深度网络模型:策略与实践
激活函数策略与选择
激活函数是神经网络中的一个关键组件,它引入非线性性质,使得神经网络能够捕获和表示复杂的模式和特征。激活函数有很多种,不同的激活函数适用于不同的问题和网络结构,选择合适的激活函数通常需要根据具体情况进行实验和调优。下面给大家介绍几种常见的激活函数。
Sigmoid:逻辑激活函数
Sigmoid激活函数的方程式如下:
$$
f(x)=\frac{1}{1+e^{-x}}
$$
Sigmoid函数图形如图1所示:
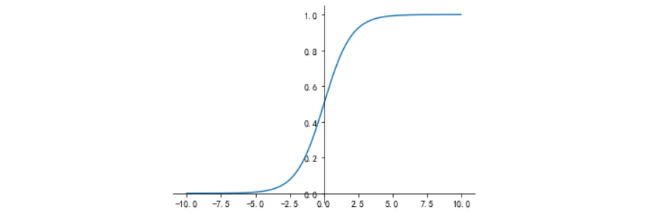
Sigmoid在定义域内处处可导,且两侧导数逐渐趋近于0。如果x的值很大或者很小的时候,那么函数的梯度(函数的斜率)会非常小,在反向传播的过程中,导致了向低层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, 网络在5层之内使用Sigmoid就会产生梯度消失现象。而且,该激活函数并不是以0为中心的,所以在实践中这种激活函数使用的很少。Sigmoid函数一般只用于二分类的输出层。
TanH:双曲正切函数
TanH激活函数的方程式如下:
$$
f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}
$$
TanH激活函数图形如图2所示:
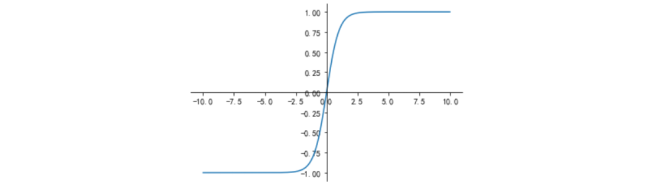
TanH也是一种非常常见的激活函数。与Sigmoid相比,它是以0为中心的,使得其收敛速度要比Sigmoid快,减少迭代次数。然而,从图中可以看出,TanH两侧的导数也为0,同样会造成梯度消失。
ReLU:修正线性单元
ReLU激活函数的方程式如下:
$$
f(x)=max(0, x)
$$
ReLU激活函数图形如图3所示:
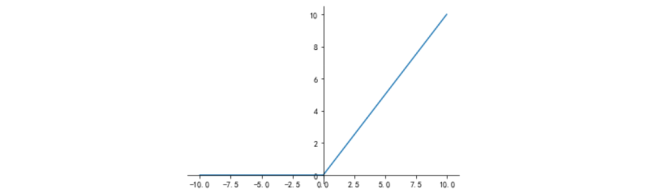
ReLU是目前最常用的激活函数。从图中可以看到,当x<0时,ReLU导数为0,而当x>0 时,则不存在饱和问题。所以,ReLU能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新,这种现象被称为“神经元死亡”。
与Sigmoid相比,ReLU的优势是:
- 采用Sigmoid函数,计算量大(指数运算),反向传播求梯度时,求导涉及除法,计算量相对大,而采用ReLU激活函数,整个过程的计算量节省很多。
- Sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Leaky ReLU:泄漏修正线性单元
Leaky ReLU激活函数的方程式如下:
$$
f(x)=max(0.1x, x)
$$
Leaky ReLU激活函数图形如图4所示:
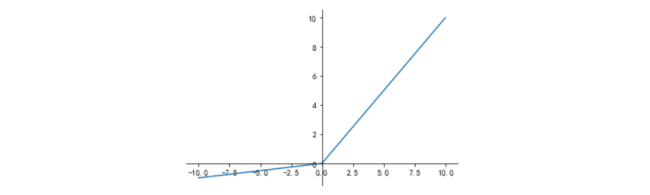
Leaky ReLU是对ReLU的改进,解决了激活“神经元死亡”问题。它在负数值上引入一个小的斜率。
Softmax:分类与概率分布
Softmax函数通常用于多类别分类问题,将多个线性输出映射为概率分布,其函数的方程式如图5所示:
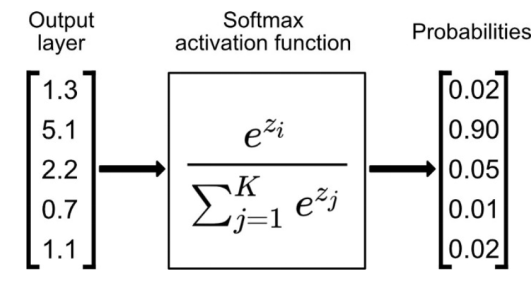
Softmax对于长度为K的任意实向量,Softmax可以将其压缩为长度为K,至于K值是多少,取决于分类的类别数量,所有经过这个函数计算后的值都在(0,1)范围内,并且向量中元素的总和为1的实向量。我们将这个实向量理解成概率的集合,选取概率最大(也就是值对应最大的),作为我们的预测目标类别。
激活函数的选择策略
最后,我们来总结一下激活函数的选择策略,如下:
隐藏层
- 优先选择ReLU激活函数。
- 若ReLU效果不好,那么尝试其他激活,如LeakyReLU等。
- 不要使用Sigmoid激活函数。
输出层
- 二分类问题选择Sigmoid激活函数。
- 多分类问题选择Softmax激活函数。
损失函数的策略与选择
在训练神经网络时,优化目标通常是最小化损失函数,以使模型能够更好地拟合数据并提高性能。神经网络损失函数(也称为目标函数或代价函数)是用于度量模型预测与实际目标之间的差异或误差的函数。选择合适的损失函数是神经网络训练的关键,因为它直接影响模型的性能和训练过程的有效性。损失函数有很多种,选择合适的损失函数通常取决于问题类型、数据分布和模型结构。下面给大家介绍几种常见的损失函数。
MAE:平均绝对值误差
平均绝对误差损失(Mean Absolute Error,MAE)是一种常用于回归问题中的损失函数,用于度量模型的预测值与实际值之间的平均绝对差异。MAE提供了一种直观的度量,表示模型的平均预测误差的大小,它不受异常值的影响,因为它是通过绝对值来计算误差的。
MAE的计算方式非常简单,对于一个包含n个样本的数据集,其公式如下:
$$
Loss=\frac{1}{n}\sum^{n}_{i=1}|z_i-y_i|
$$
其中:
- n 是样本数量,i表示第几个样本。
- $y_i$是第i个样本的实际目标值。$z_i$是第$i$个样本的模型预测值。
MAE的值越小表示模型的预测越准确,因为它衡量了模型的平均绝对误差。与均方误差损失(Mean Squared Error,MSE)不同,MAE不会对误差进行平方,因此它对异常值的敏感性较低。这使得MAE在某些情况下更稳健,尤其是当数据中存在离群值或异常值时。MAE适用于许多回归任务,尤其是那些要求模型对误差保持一致关注的情况。然而,与MSE相比,MAE通常更难以优化,因为它不提供梯度信息。因此,在训练神经网络时,有时会使用MSE或其他损失函数,并在评估时使用MAE来衡量模型的性能。
MSE:均方误差
均方误差(Mean Squared Error,MSE)是一种用于度量回归模型性能的常见损失函数。它在统计学和机器学习中广泛用于衡量模型的预测值与实际值之间的平均平方误差。
MSE的计算方非常简单,对于一个包含n个样本的数据集,其公式如下:
$$
Loss=\frac{1}{n}\sum^{n}_{i=1}(z_i-y_i)^2
$$
其中:
n 是样本数量,i表示第几个样本。
$y_i$是第$i$个样本的实际目标值。$z_i$是第$i$个样本的模型预测值。
均方误差的值越小,表示模型的预测越接近实际值,因此MSE越小通常意味着模型性能越好。均方误差是一个可微分的损失函数,因此在优化过程中可以使用梯度下降等基于梯度的优化算法。这使得它在深度学习中广泛使用,因为深度学习模型通常需要梯度信息来进行训练。均方误差对于许多回归问题具有数学上的解,这意味着可以通过解均方误差的梯度来找到最小化均方误差的模型参数。尽管均方误差在许多回归问题中表现良好,但它也有一些局限性。例如,它对异常值(离群点)非常敏感,可能会导致模型对异常值过于敏感,从而影响了模型的稳健性。因此,在应用均方误差时,需要谨慎处理异常值,并考虑是否有更适合特定问题的损失函数。
Cross Entropy:交叉熵
交叉熵损失函数(Cross-Entropy Loss),也称为对数损失(Log Loss),是一种广泛用于分类问题的损失函数。它用于衡量模型的分类输出与实际类别标签之间的差异。交叉熵损失在深度学习和机器学习中非常常见,特别是在神经网络的分类任务中。
Cross-Entropy Loss的计算方较为复杂,对于一个包含n个样本的数据集进行二分类任务,其公式如下:
$$
Loss=-\frac{1}{n}\sum^n_{i=1}[y_i\cdot\log{z_i}+(1-y_i) \cdot \log({1 - z_{i}})]
$$
其中:
- $n$表示样本数量,$i$表示第几个样本。
- $y_i$是第i个样本的实际目标概率值。$z_i$是第$i$个样本的模型预测概率值。
对于一个包含n个样本的数据集进行多分类任务,其公式如下:
$$
Loss=-\frac{1}{n}\sum^n_{i=1}\sum^m_{j=1}y_{ij}\cdot\log(z_{ij})
$$
其中:
- $n$表示样本数量,$i$表示第几个样本。
- $m$表示分类,$j$表示第几个类别。
- $y_ij$表示第i个样本属于第j个类别的实际目标概率值。$z_ij$表示第i个样本属于第j个类别的模型预测概率值。
交叉熵损失的直观解释是衡量模型对于每个样本的实际标签所对应的概率估计与实际标签的差异,然后对所有样本取平均。这个损失函数鼓励模型使得实际标签所对应的类别的概率尽可能接近1,而其他类别的概率尽可能接近0。交叉熵损失函数在分类问题中是一种非常常见且有效的损失函数,它能够衡量模型输出与实际标签之间的差异,并可以用于训练和评估分类模型的性能。
损失函数的选择策略
最后,我们来总结一下损失函数的选择策略,如下:
对于回归问题:
- 数据具有长尾分布(存在极端值或异常值)使用平局绝对值误差(MAE)。
- 数据不具有长尾分布异常值少使用均方误差(MSE)。
对于分类问题:
- 二分类使用二分类交叉熵(binary cross entropy)损失函数。
- 多分类使用分类交叉熵(categorical cross entropy)损失函数。
参数初始化及选择
参数初始化又称为权重初始化(weight initialization)。深度学习模型训练过程的本质是对权重进行更新,这需要每个参数有相应的初始值,前面章节讲的预测打车费用例子就做过这样的操作。说白了,训练神经网络其实就是对权重参数不停地迭代更新,以达到较好的性能。
在深度学习中,神经网络的权重初始化方法对对模型的收敛速度和性能有着至关重要的影响。在深度神经网络中,随着层数的增多,我们在梯度下降的过程中,极易出现梯度消失或者梯度爆炸,至于梯度消失与梯度爆炸我们后面给大家讲解。一个好的权重初始化虽然不能完全解决梯度消失和梯度爆炸的问题,但是对于处理这两个问题是有很大的帮助的,并且十分有利于模型性能和收敛速度,在某些网络结构中甚至能够提高准确率。因此,对权重的初始化则显得至关重要。参数初始化方式有很多,接下我们会给大家介绍常见的几种。
随机初始化
随机初始化是神经网络参数初始化的一种常见方法,它涉及将神经网络的权重和偏差初始化为从某个随机分布中抽取的值。这个方法的目的是打破权重的对称性,为网络提供一些随机性,以便在训练期间学习不同的特征。以下是关于随机初始化的详细介绍:
初始化分布,在随机初始化中,通常使用均匀分布或正态分布来生成随机数作为权重和偏差的初始值。这两种分布具有以下特性:
- 均匀分布(Uniform Distribution):从均匀分布中生成的随机数在一个特定范围内均匀分布。在初始化时,通常会选择一个范围,例如[-a, a],然后从这个范围中随机抽取值来初始化权重和偏差。这有助于确保初始值不会过大或过小,避免了梯度爆炸或梯度消失问题。
- 正态分布(Normal Distribution):从正态分布中生成的随机数遵循钟形曲线分布。在初始化时,通常会选择均值(平均值)和标准差,然后从这个正态分布中随机抽取值来初始化参数。正态分布的初始值通常更接近于零,但标准差的选择可以控制初始值的分布范围。
偏置的初始化:对于偏差项(bias),通常可以将它们初始化为零,因为偏差的主要作用是平移激活函数。然而,一些特定的网络架构和任务可能会采用不同的初始化策略。
Xavier初始化
Xavier初始化,也称为Glorot初始化,是一种用于神经网络参数初始化的方法,旨在有效地处理梯度消失或梯度爆炸问题,特别是在使用Sigmoid和Tanh等S型激活函数时。这种初始化方法的核心思想是根据网络的输入和输出尺寸来自适应地选择权重的初始值,以确保在前向传播和反向传播过程中梯度保持稳定。与传统的随机初始化相比,Xavier初始化更加智能化,可以提高网络的训练效率和性能。
Xavier初始化通过使用以下公式计算权重的初始值:
$$
W\text{~}U[-\frac{1}{\sqrt{n}},\frac{1}{\sqrt{n}}]
$$
其中:
- W表示权重矩阵。
- U(a, b)表示从均匀分布中随机抽取值,范围在a到b之间。
- n表示输入参数的个数。
Xavier初始化的特点是根据输入和输出单元的数量来动态选择权重的初始范围。这意味着对于具有不同规模的网络层,Xavier初始化会自适应地调整初始值的大小。当输入和输出单元的数量较大时,初始值会较小,反之亦然。
与随机初始化相比,Xavier初始化具有以下优势:
- 梯度尺度稳定性:Xavier初始化旨在保持前向传播和反向传播过程中梯度的尺度稳定。这有助于防止梯度消失或梯度爆炸问题,从而使网络更容易训练。
- 加速收敛:由于权重的初始范围是根据网络规模动态选择的,因此网络通常会更快地收敛,减少了训练时间。
- 适用于S型激活函数:Xavier初始化特别适用于使用S型激活函数(如Sigmoid和Tanh)的网络层,因为这些激活函数具有均值接近0的性质。
He初始化
He初始化,命名自其作者Kaiming He,是一种用于神经网络参数初始化的方法,特别适用于使用ReLU(修正线性单元)等非线性激活函数的网络。He初始化的目标是解决梯度消失问题,确保在网络的训练过程中梯度传播得更加稳定,从而加速训练并提高模型性能。
He初始化通过使用以下公式计算权重的初始值:
$$
W\text{~}Normal(0,\sqrt\frac{2}{n})
$$
其中:
W表示权重矩阵。
$Normal(0,\sqrt\frac{2}{n})$表示从均值为0、标准差为$\sqrt\frac{2}{n}$正态分布中随机抽取值。
n表示输入参数的个数。
He初始化的特点: He初始化旨在确保梯度在前向传播和反向传播中的尺度保持稳定。与Xavier初始化不同,He初始化使用较大的标准差,以适应ReLU激活函数的特性。这有助于避免梯度消失问题。
与随机初始化相比,He初始化具有以下优势:
- 更适用于ReLU:He初始化专门为ReLU激活函数设计,而随机初始化是通用的初始化方法。在使用ReLU时,He初始化通常会导致更好的训练效果,因为它可以更好地利用ReLU的非线性性质。
- 梯度稳定性:He初始化的使用可以提高梯度传播的稳定性,从而有助于更快地收敛和更好的模型性能。
预训练初始化
预训练初始化是一种用于神经网络的参数初始化方法,它利用在大规模数据集上预训练的模型的权重和参数作为初始值,然后在特定任务上进行微调,可以加速特定任务上的训练过程,并提高模型性能。这种方法已经在深度学习领域取得了巨大的成功,特别是在自然语言处理和计算机视觉等领域。
下面给大家介绍一下预训练模型的生成过程:
- 预训练阶段:
- 使用大规模的数据集和任务来训练一个深度神经网络模型,通常是一个非常深层次的模型。这个阶段的任务可能与最终要解决的任务不同,但是它可以帮助模型学习到有用的特征表示和知识。
- 模型参数保存:一旦预训练模型在预训练任务上训练完成,模型的参数(包括权重和偏差)会被保存下来。
- 微调阶段:使用预训练模型的参数来初始化特定任务的神经网络,然后在该任务上进行微调。微调阶段的步骤如下:
- 加载预训练模型参数:预训练模型的参数被加载到特定任务的神经网络中。
- 锁定一部分层(可选):通常,预训练模型的一部分层(通常是前面的层)会被锁定,不进行微调。这是因为低层次的特征通常是通用的,而高层次的特征则更适合特定任务。锁定低层次的层可以防止过度拟合,加速微调过程。
- 微调:在特定任务上进行微调,通常通过梯度下降或其变种来调整网络的参数,使其适应新任务。
- 预训练初始化的优势:
- 迁移学习:预训练初始化利用了在大规模数据上训练的模型的知识,这可以提高模型在特定任务上的性能,尤其是当特定任务的数据有限时。
- 特征提取:预训练初始化使模型学习到有用的特征表示,这些表示可以在微调过程中用于特定任务,减少了需要手工设计特征的工作。
- 加速收敛:由于模型已经学到了一些有用的知识,预训练初始化通常会加速微调的收敛,使模型更快地达到良好的性能。
参数初始化的选择策略
最后,我们来总结一下参数初始化的选择策略,如下:
- 如果你计划使用迁移学习,那么你可能会首先考虑使用预训练初始化,然后根据任务需求微调模型。
- 如果你在使用深度学习框架时,通常会有内置的初始化方法,可以根据需要轻松设置。这些内置方法通常已经针对不同类型的层和激活函数进行了优化。
- 对于S型激活函数(如Sigmoid和Tanh),Xavier初始化通常是一个合理的默认选择。
- 对于ReLU激活函数,He初始化通常是一个合理的默认选择,因为它更好地适应ReLU的非线性性质。
过拟合与正则化策略
过拟合
拥有大量的自由参数的模型能够描述特别神奇的现象。即使这样的模型能够很好的拟合已有的数据,但并不表示是一个好模型。因为这可能只是因为模型中足够的自由度使得它可以描述几乎所有给定大小的数据集,而不需要真正洞察现象的本质。所以发生这种情形时,模型对已有的数据会表现的很好,但是对新的数据很难泛化。对一个模型真正的测验就是它对没有见过的场景的预测能力。这种现象,我们称之为过拟合,与之相反的现象就是欠拟合。
大家可能有些不能理解,这里我们分别举两个例子。第一个例子,大家都参加很多次考试,每次考试前大家都会抓紧复习,但依然发现自己的考试成绩并不理想,因为可能考试的内容不是你复习过的内容,导致你复习出现了过拟合,你只会做你复习的内容,不会做你没有复习过的内容。第二个例子,比如我们要做一个识别天鹅的神经网络,但我们喂给神经网络的数据全是白色的天鹅,这样就会导致训练出来神经网络过拟合了现有数据,认为天鹅就必须是白色得。如果我们把一张黑色天鹅给神经网络,这就会导致神经网络识别成不是天鹅。
那出现这种过拟合问题,怎么解决呢?大部分人第一时间想到的是添加训练数据,比如给上面第二个例子的神经网络喂的数据包含各种颜色的天鹅即可。虽然这种方式看着可行,但有时我们并不能拿到全面的数据,覆盖各种情况,那我们怎么办呢?这时我们就使用正则化。正则化是通过在损失函数中引入额外的惩罚项,迫使模型的参数保持在较小的范围内,从而限制了模型的复杂度。这有助于使模型更一般化,更适应未见过的数据。接下我们会给大家介绍常见的几种正则方式。
L1正则化
L1 正则化是一种用于机器学习和深度学习中的正则化技术,它旨在减小模型的复杂度并防止过拟合。L1 正则化是通过在损失函数中引入 L1 范数(绝对值的和)的惩罚项来实现,从而迫使模型的参数保持较小的值,从而提高了模型的泛化能力和解释性。
通常,神经网络的损失函数由两部分组成:损失函数(通常是均方误差或交叉熵等)和正则化项。加入L1正则化损失函数如下:
$$
Loss=Loss_0+\lambda\sum^n_{i=1}|w_i|
$$
其中:
- $\lambda$表示称为正则化强度或超参数的常数,用于控制正则化的程度。较大的$\lambda$会导致更强烈的正则化,从而使模型参数更趋向于零。
- n表示模型参数的总数量。
- $w_i$表示模型的第i个参数。
- $Loss_0$原本的损失函数。
L1 正则化的主要作用是促使模型的参数向量变得稀疏,即使其中的某些参数趋向于零。这种稀疏性可以被视为一种特征选择机制,因为它使模型倾向于忽略不重要的特征或属性。当某些特征在任务中不起作用或冗余时,L1 正则化可以帮助模型识别和使用最重要的特征。
L1 正则化的另一个作用是防止过拟合。过拟合通常发生在模型复杂度过高时,模型过度拟合训练数据中的噪声和细微特征。通过迫使参数趋向于零,L1 正则化可以降低模型的复杂度,减少了过拟合的风险,提高了模型的泛化能力。
L2正则化
L2 正则化(也称为权重衰减或L2范数正则化)是一种用于机器学习和深度学习中的正则化技术,旨在减小模型的复杂度以防止过拟合。L2 正则化是通过在损失函数中引入 L2 范数(权重的平方和)的惩罚项来实现,从而迫使模型的参数保持较小的值,从而提高了模型的泛化能力和解释性。
通常,神经网络的损失函数由两部分组成:损失函数(通常是均方误差或交叉熵等)和正则化项。加入L2正则化损失函数如下:
$$
Loss=Loss_0+\lambda\sum^n_{i=1}w_i^2
$$
其中:
- $\lambda$表示称为正则化强度或超参数的常数,用于控制正则化的程度。较大的$\lambda$会导致更强烈的正则化,从而使模型参数更趋向于零。
- n表示模型参数的总数量。
- $w_i$表示模型的第i个参数。
- $Loss_0$原本的损失函数。
L2 正则化的主要作用是限制模型参数的幅度,迫使它们不要变得过大。这有助于防止过拟合,因为大的参数值可能导致模型对训练数据中的噪声和细微特征过于敏感。通过保持参数值较小,L2 正则化有助于提高模型的泛化能力,使其在未见过的数据上表现更好。
L2 正则化还可以被视为一种控制模型复杂度的方法。通过向损失函数中添加 L2 正则化项,模型训练过程中将更倾向于选择参数值较小的配置,这可以降低模型的复杂度。这在某些情况下可以有助于改善模型的解释性和通用性。
Dropout
Dropout正则化是⼀种相当激进的技术。和L2正则化不同,其并不依赖对损失函数的修改。而是,在 Dropout中,我们改变了网络本身。在介绍它为什么能工作,以及所得到的结果前,让我描述一下Dropout基本的工作机制。假设我们尝试训练一个网络,如图6所示:
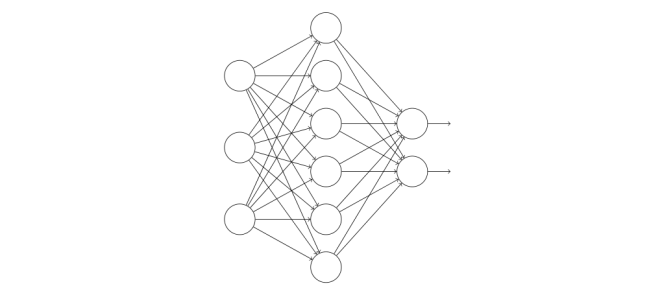
假设我们有一个训练数据x和对应的目标输出y。通常我们会通过在网络中前向传播x,然后进行反向传播来确定对梯度的贡献。使用Dropout技术,这个过程就改了。我们会从随机地删除网络中的一半的隐藏神经元开始,同时让输入层和输出层的神经元保持不变。在此之后,我们会得到最终如下线条所示的网络。注意那些被Dropout的神经元,即那些临时被删除的神经元,用虚圈表示,如图7所示:
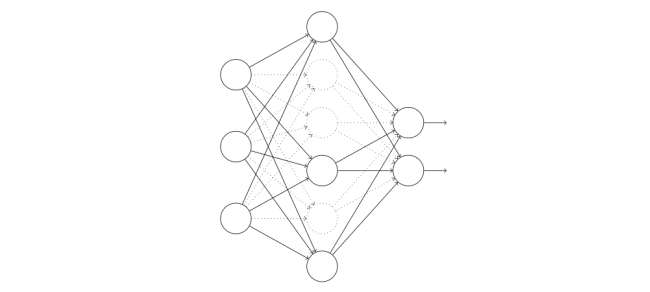
我们前向传播输入x,通过修改后的网络,然后反向传播结果,同样通过这个修改后的网络。在一个小批量数据的若干样本上进行这些步骤后,我们对有关的权重和偏置进行更新。然后重复这个过程,首先重置弃权的神经元,然后选择一个新的随机的隐藏神经元的子集进行删除,估计对一个不同的小批量数据的梯度,然后更新权重和偏置。
通过不断地重复,我们的网络会学到一个权重和偏置的集合。当然,这些权重和偏置也是在一半的隐藏神经元被Dropout的情形下学到的。这个Dropout过程可能看起来奇怪, 像是临时安排的。 为什么我们会指望这样的方法能够进行正则化呢?为了解释所发生的事,我希望你停下来想一下标准(没有Dropout)的训练方式。特别地,想象一下我们训练几个不同的神经网络,都使用同一个训练数据。当然,网络可能不是从同一初始状态开始的,最终的结果也会有一些差异。出现这种情况时,我们可以使用一些平均或者投票的方式来确定接受哪个输出。这种平均的方式通常是一种强大(尽管代价昂贵)的方式来减轻过拟合。原因在于不同的网络可能会以不同的方式过拟合,平均法可能会帮助我们消除那样的过拟合。
那么这和Dropout有什么关系呢?换个角度地看,当我们Dropout掉不同的神经元集合时,有点像我们在训练不同的神经网络。所以,弃权过程就如同大量不同网络的效果的平均那样。不同的网络会以不同的方式过拟合了,所以,弃权过的网络的效果会减轻过拟合。
正则化的选择策略
首先在此提醒,不管哪种正则化方式,只有当出现过拟合的情况下才使用上面这些正则化方式。选择适当的正则化方法和超参数需要一定的实验和经验,以下是一些指导原则,可帮助你在选择正则化方法时做出合适的决策:
L1正则化:
特征选择:当你的数据集包含大量特征,但你认为只有一小部分特征对问题的解决非常重要时,L1正则化可以用于特征选择。它倾向于使模型的权重稀疏,将某些特征的权重设为零,从而实现特征选择的效果。
噪声或冗余特征:如果你怀疑数据中存在噪声或冗余特征,L1正则化可以帮助模型忽略这些不重要的特征,提高模型的鲁棒性。
L2正则化:
权重衰减:L2正则化通常被视为权重衰减的一种形式,可以帮助防止权重变得过大。这对于避免过拟合和提高模型的泛化能力非常有用。
防止权重爆炸:在深度神经网络中,如果权重值变得非常大,可能会导致梯度爆炸问题。L2正则化可以限制权重的增长,有助于缓解这个问题。
Dropout:
神经网络正则化:Dropout是一种专门用于神经网络的正则化技术。它通过在训练过程中随机关闭一些神经元来减少神经元之间的依赖关系,从而减小模型的复杂度。选择Dropout取决于你是否使用神经网络作为模型,以及你是否希望通过随机关闭神经元来防止过拟合。
强大的正则化:Dropout通常被认为是一种强大的正则化方法,特别适用于深度神经网络和大规模数据集。如果你的模型非常复杂,数据量有限,而且你担心过拟合,可以考虑使用Dropout。
梯度与学习率的优化
在深度学习中,梯度与学习率的优化是非常重要的,因为它们直接影响模型的训练速度和性能。这一章节我会为大家讲解梯度下降、学习率调度及优化算法等等。
梯度下降
梯度下降学习算法有三种类型:批量梯度下降、随机梯度下降和小批量梯度下降,详细介绍如下:
批量梯度下降算法(BGD)会将训练集中每个点的误差相加,只有在所有训练示例都被评估后才更新模型。 这个过程被称为训练周期。虽然这种批量处理增加了一定的计算效率,但对于大型训练数据集,它仍然需要很长的处理时间,因为它仍然需要将所有数据存储到内存中。批量梯度下降算法通常也会产生稳定的误差梯度和收敛性,但有时在寻找局部最小值和全局最小值时,收敛点并不是最理想的。
随机梯度下降 算法 (SGD) 为数据集中的每个示例运行一个训练周期,并一次性更新所有训练示例的参数。由于你只需要保存一个训练示例,所以可以更轻松地将参数存储在内存中。虽然这些频繁的更新可以使计算更加详细,速度更快,但与批量梯度下降算法相比,这可能会导致计算效率下降。随机梯度下降算法的频繁更新可能导致梯度变得嘈杂,但这也有助于避开局部最小值,并找到全局最小值。
小批量梯度下降(MBGD)算法结合了批量梯度下降算法和随机梯度下降算法的理念。它将训练数据集分割成小 批量,并对每批进行更新。该方法兼顾了批量梯度下降算法的计算效率和随机梯度下降算法的速度。
接下来我们详细看下三种梯度下降算法在准确度,性能等方面的对比,如表8:
| 批量梯度下降 | 随机梯度下降 | 小批量梯度下降 | |
|---|---|---|---|
| 数据处理 | 使用整个训练集进行每次迭代的梯度计算 | 使用单个样本进行每次迭代的梯度计算 | 使用一小批样本进行每次迭代的梯度计算 |
| 训练效率 | 每次迭代需要较长时间 | 每次迭代非常快 | 较快于批量梯度下降 |
| 收敛速度 | 较慢,但通常能达到较好的收敛 | 较快,但可能会出现震荡 | 较快,通常在批量和随机之间 |
| 准确度 | 较好的准确度 | 较高的噪声,可能需要更多的迭代 | 较好的准确度 |
| 计算资源 | 占用高 | 占用小 | 占用中等 |
| 适用场景 | 适用于小型数据集,可以收敛到全局最小值 | 适用于大型数据集,有可能跳出局部最小值 | 适用于中等大小数据集,平衡速度和性能 |
需要注意的是,选择哪种梯度下降算法取决于具体问题、数据集大小和计算资源。通常情况下,小批量梯度下降是最常用的方法,因为它在训练效率和模型性能之间取得了平衡。然而,对于大型数据集,随机梯度下降可能更具吸引力,因为它具有更快的收敛速度。批量梯度下降通常适用于小型数据集,但需要更多的计算资源。因此,根据问题的具体要求,可以选择不同的梯度下降算法。
学习率调度
学习率是控制每次参数更新步长的超参数。它决定了模型在每次迭代中沿着梯度方向移动的距离。学习率太小可能导致训练过于缓慢,而学习率太大可能导致训练不稳定,甚至发散。所以学习率的设置就至关重要,这里引出我们接下来要讲的学习率调度。
学习率调度(Learning Rate Scheduling)是深度学习中的一种技术,用于动态调整训练过程中的学习率。学习率是控制模型参数更新步长的超参数,它在训练中非常重要,学习率调度是优化深度学习模型训练的重要技术之一。适当调整学习率和使用合适的学习率调度策略可以帮助模型更快地收敛到最优解,提高泛化能力,减轻过拟合问题,并改善训练过程的稳定性。学习率调度的类型有很多种,常见的有以下几种:
按指数退火(Exponential Decay):学习率按指数函数减小,例如$a_t=a_0\cdot e^{-kt}$,其中是$a$第$t$次迭代的学习率,$a_0$是初始学习率,$k$是衰减速度。
按余弦退火(Cosine Annealing):学习率按余弦函数变化,通常在一个周期内逐渐减小,然后再次增加。这种调度方式通常用于训练循环神经网络(RNN)等模型。
自适应学习率(Adaptive Learning Rate):根据模型性能自动调整学习率。例如,如果模型在验证集上的性能停止提升,就可以降低学习率,以帮助模型更好地收敛。
学习率衰减(Learning Rate Decay):学习率在每个训练周期或一定迭代次数后以固定比例进行减小。
学习率重启(Learning Rate Warmup and Restart):在训练初期使用较小的学习率,然后逐渐增加它,以帮助模型更好地探索参数空间。
通常,学习率调度方法需要根据具体问题、模型架构和数据集进行调整。最佳的学习率调度方法可能因问题而异,这里提供几点意见:
通过尝试不同的学习率调度策略并观察验证集上的性能,可以确定哪种策略最适合您的问题。
自适应学习率方法如Adam和RMSprop等通常能够自动调整学习率,因此在许多情况下是一个不错的选择。