前言
近年来,大家可以察觉到生成式AI发展得非常迅猛:有视觉的、文本大语言的、语音的、音乐的等等。市场上有很多大型语言模型可以选择,有些是开源的,有些不是开源的, 以至于容易令许多开发者产生疑问:我该使用哪一个大语言模型呢?
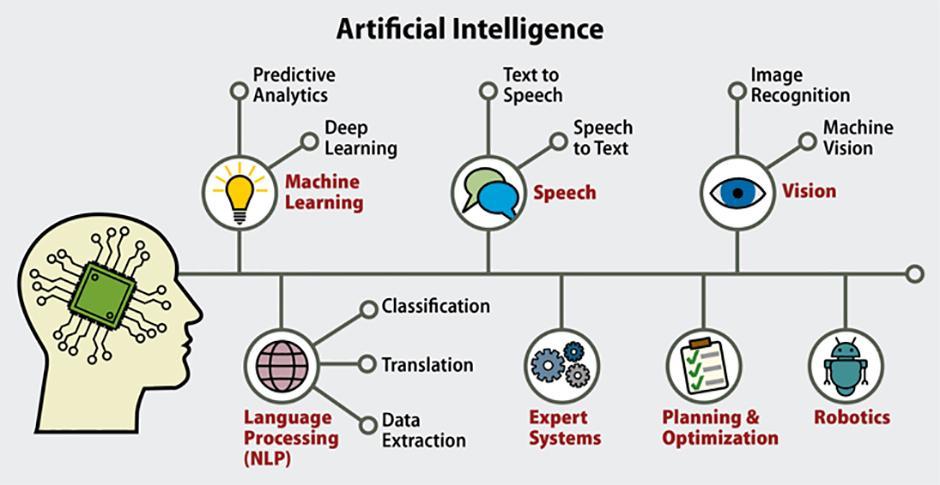
那么现在的大语言模型参数量是如何?我们应该如何选择?
若你想拥有一个大语言模型,能够掌握世界上的各种海量知识时,比如关于历史、哲学、天文、地理、亦或是让其编写Python代码等的东西时。 使用一个包含数千亿个参数的巨型模型是不错的方案。
但是对于单项任务,例如我只需要进行信息提取或让大模型充当一家公司在线智能客服来回答客户问到的公司产品问题的时候,对于这样的需求, 则不需要大语言模型,使用参数更少的模型也能完成相同的任务。
我们讨论一下大语言模型在日常生活中的应用与任务:
聊天机器人
从文本生成图像
结合编程插件来让大语言模型辅助写代码
翻译
信息摘要
信息提取
生成文章
从这些工具中看到生成式AI是一个 能够创建模仿或近似人类能力的内容 的机器。
生成式 AI 是传统机器学习的一个子集。 通过在最初由人类编写的海量内容数据集中通过发现、统计其中的模式来学习人类的能力。
大语言模型在算力允许的前提下,能在数周和数月内完成对数万亿个单词的训练。
而这些基础模型,具有数十亿个参数,除了语言之外,还表现出新出现的特性。研究人员正在激发大语言模型的潜能,使之拥有分解、推理和解决复杂任务能力。
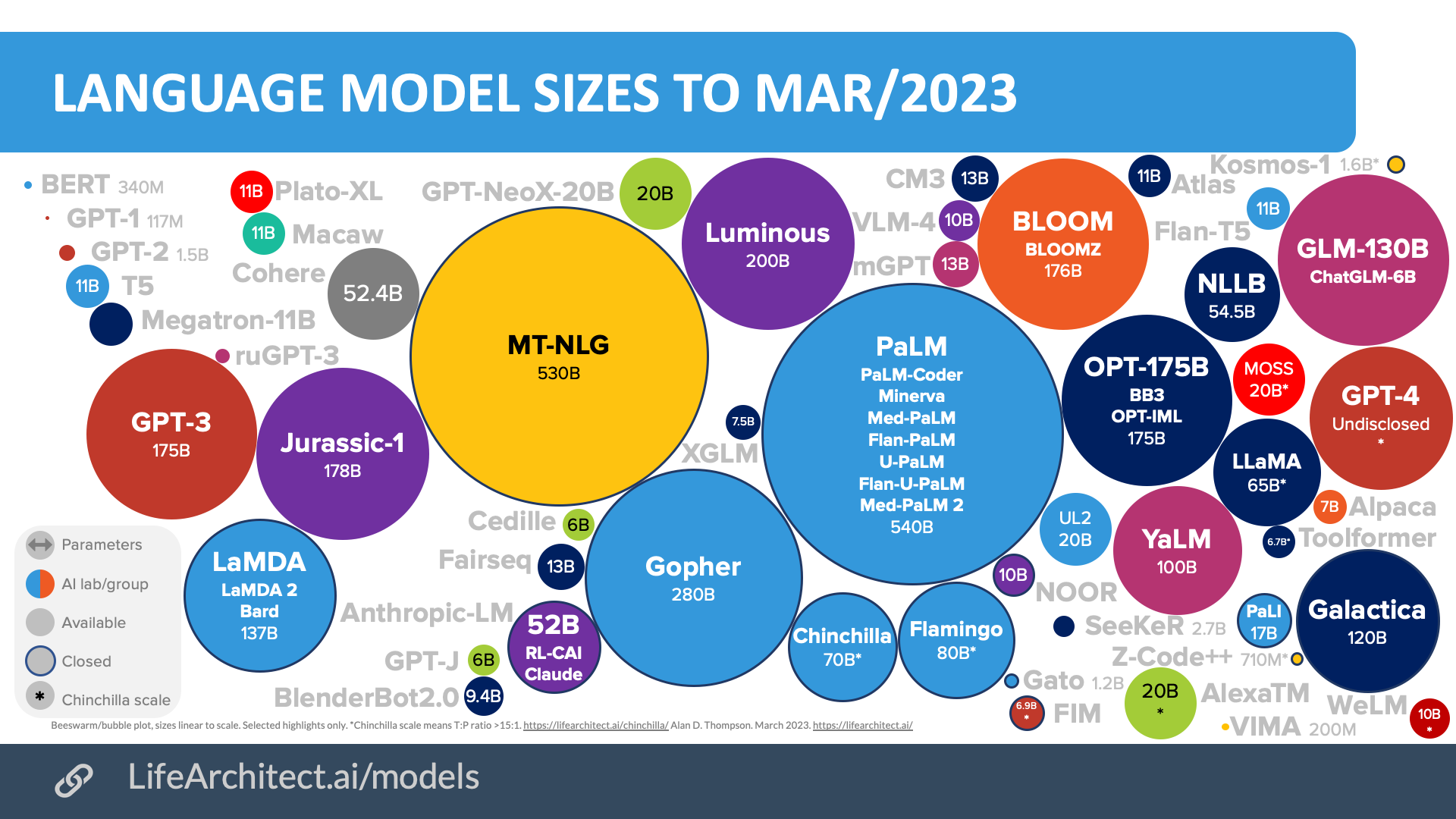
以下是基础模型的集合,有时也称为基础模型,以及它们在参数方面的相对大小。 稍后你将更详细地介绍这些参数,但现在可以把参数当作模型的所占的内存空间。
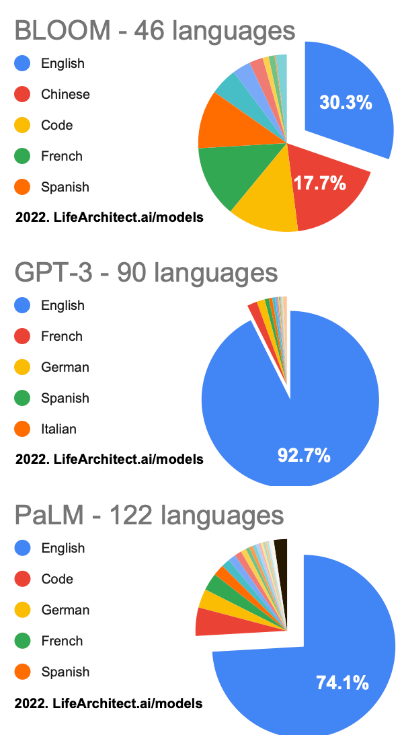
可以通过以下几个模型观察,大模型学习的知识库中各种语言的占比。
若在本机进行实验的话,我们可以选用开源的大语言模型例如Flan-t5来执行语言任务。
一个缩小版的”大语言模型”部署:可以将如下代码复制到Jupyter Notebook中执行。
1 | from transformers import AutoModelForSeq2SeqLM, AutoTokenizer |
此段代码中的模型可以替换成:
我们可以直接使用这些模型,亦或通过应用微调技术让它们适用于特定用例,用现有的大语言模型可以快速构建自定义解决方案,从而无需从头开始训练新模型。
现在,虽然生成式AI有针对不同的领域,如生成图像、视频、音频和语音这些。但在本课程中,将重点介绍大型语言模型及其在自然语言生成中的用途。
在这个课程中,将看到大语言模型是如何构建和训练的,如何通过提示文本与大语言模型互动、如何针对你的用例对大语言模型微调模型、如何将它们与应用程序一起部署以解决业务和社交任务。
与大语言模型交互的方式跟其他机器学习和编程范式是截然不同的。
在传统的编程情况下,我们通常需要使用具体的编程语法去编写计算机代码来调用库和API进行交互。相比之下,大型语言模型能够像人类一样可以接受自然语言或人类书面指令去执行任务。
通过例子来提前说明一些关于LLM名词,例子:现在要求模型回答一个问题:”明天星期日,后天星期几?”,将这句提示词传递给模型,让模型给出答案。
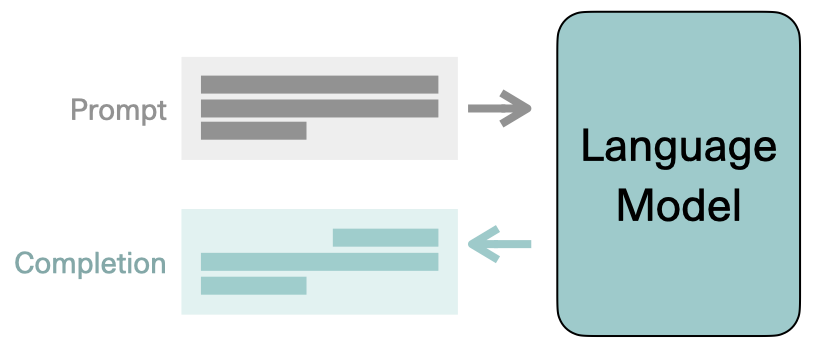
而我们传递给 LLM 的文本称为提示词(Prompt)。
提示词可用的空间或内存称为上下文窗口(Context Window),它通常足够容纳几千个单词,但大语言模型的型号不同而不同。
在这个过程中,模型的输出称为完成(Completion)、模型生成文本的行为称为推理(Inference),完成由原始提示中包含的文本和生成的文本所组成。
第一章 ChatGLM、LangChain、Azure OpenAI、向量数据库的基础介绍
1.1 ChatGLM3介绍
github地址:https://github.com/THUDM/ChatGLM-6B

ChatGLM3是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型,其系列中的开源模型 ChatGLM3-6B,在继承了前两代模型如对话流畅性和低部署门槛等优点的基础上,带来了以下新特性:
- 更强大的基础模型:ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base,使用了更加多样化 training data,更充分的训练步数,以及更合理的训练策略。
- 更完整的功能支持:ChatGLM3-6B 采用了全新设计的 Prompt 格式,除了能够进行正常的多轮对话外,还原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景的需求。
- 更全面的开源序列:此次不仅开源了对话模型 ChatGLM3-6B,还包括了基础模型 ChatGLM3-6B-Base 和长文本对话模型 ChatGLM3-6B-32K。所有开源模型的权重都对学术研究完全开放,且在完成问卷登记后,也允许免费商业使用。
1.2 LangChain介绍
官网地址:https://www.langchain.com/
LangChain 是一个开源框架,它可以帮助软件开发人员将大型语言模型(LLM)与自家的软件产品相结合,使得LLM能集成和应用到自己的应用程序中去。应用程序可以利用LLM的强大能力,如OpenAI的GPT-3.5和GPT-4,来处理自然语言处理(NLP)任务。
LangChain 的主要特点包括:
集成外部数据源:LangChain 允许开发者将LLM与各种外部数据源和API集成,从而创建功能丰富的NLP应用程序。
多语言支持:LangChain 提供了Python、JavaScript和TypeScript等多种编程语言的软件包,使得不同背景的开发者都能够使用这个框架。
开源项目:LangChain 由联合创始人 Harrison Chase 和 Ankush Gola 于2022年推出,作为一个开源项目,它的初始版本也在同一年发布。
易于使用:LangChain 设计为易于使用,使得即使是没有深度学习背景的开发者也能够轻松地构建和部署LLM驱动的应用程序。
1.3 Azure OpenAI介绍

Azure OpenAI 是在微软的 Azure 云平台上提供的ChatGPT服务,开发人员可以轻松地将 GPT-3.5 集成到自己的应用程序中。
1.3.1 注册 Azure 账号
注册国版 Azure 账号
Azure OpenAI Service 是 Azure Cognitive Services 的一部分,所以需要先注册 Azure 账号。目前只在 Azure 国际版上提供,所以请到 Azure 国际版 上注册账号。
地区与手机号验证
注册时可以选择 中国 地区,这样你可以直接输入 +86 的手机号进行验证。注册中国地区的账号也可以申请 Azure OpenAI Service。
1.3.2 信用卡验证
账单地址应该与你选 国家/地区保持一致,否则会提示注册失败。
1.3.3 申请 Azure OpenAI Service 试用
Azure OpenAI Service 目前需要以企业的身份来申请试用。如果你的 Azure 账号已经注册好了,可以点击 这里 来申请。
Azure OpenAI Service 接受来自中国的企业申请,请依照表单 如实填写 信息,其中最重要的是:
- Your Company Email Address:请填写你在你公司的企业邮箱地址。
- Your Company Name:请填写你所在公司的名称。
- Azure Subscription ID:请根据表单内的提示来获取你的 Azure
Subscription ID,千万不要填错成Tenant ID了,否则无法通过或者看不到订价层。 - Company Website:请填写你所在公司的网站的网址。网址里最好能展示一个与你企业邮箱地址同一个域名的邮箱地址。
- 你的企业邮箱的域名、公司网站的域名需要保持一致,域名的主体需要与公司的名称保持一致,否则会在审核时被拒绝。
- 如果你填写的资料存在明显的问题,Azure 甚至不会给你任何回复。
- 如果你填写的资料还需要进一步的证明材料,Azure 会给你发送邮件要求提供。
运气好的话,一般两天能通过审核,如果超过两周没有收到审核结果,请尝试重新提交申请。
1.3.4 部署 Azure OpenAI Service
恭喜你已经申请到了 Azure OpenAI Service 的试用资格,接下来就是部署 Azure OpenAI Service 了。

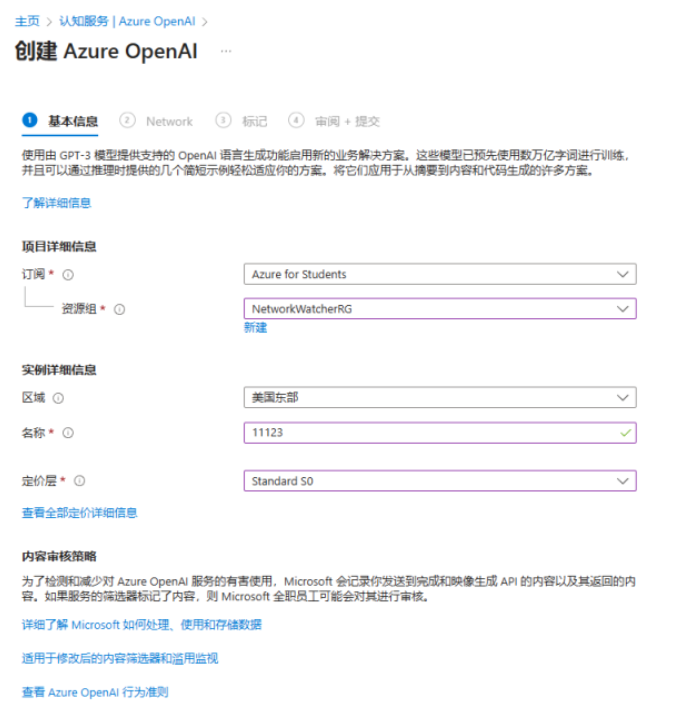
登录到 Azure 以后,你会在首页的 Azure services 里面看到 Azure OpenAI 的图标,点击进入来创建部署 OpenAI Service 资源。
- 在创建Azure OpenAI的页面,订阅
-资源组一栏如果没有,新建一个即可。 - 在名称一栏根据要求输入一个简短好记的资源名,未来需要通过它来访问你的私有 OpenAI API。
- 定价层选择默认选项。
- 标记一页,如果你不需要通过 tags 来管理自己的资源,可暂时不填。
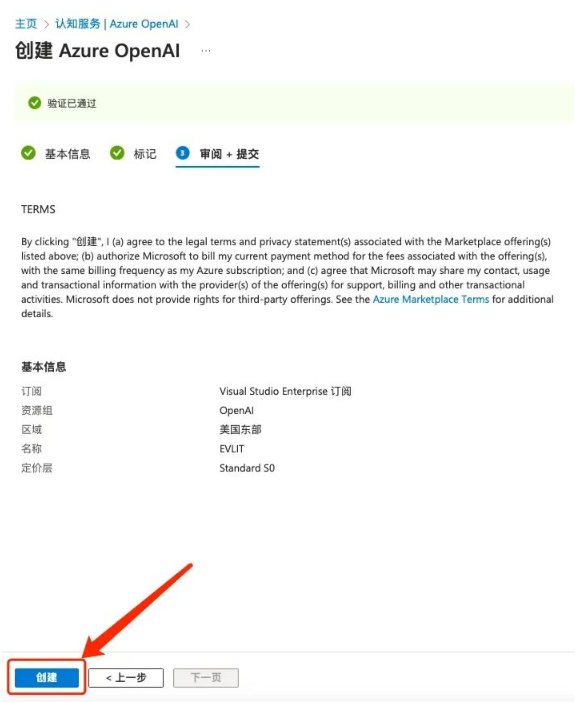
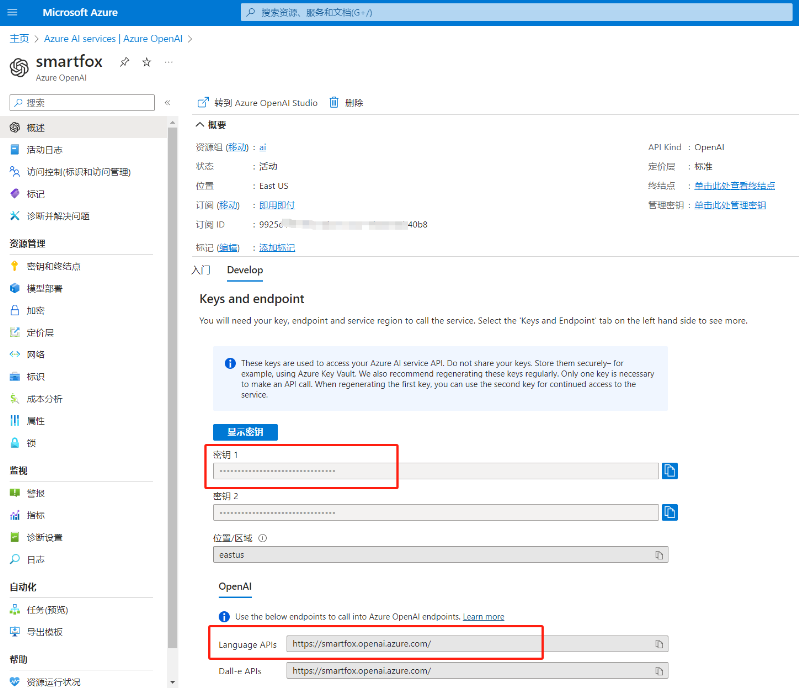
- 在审阅+提交之后,即可进入部署阶段,部署资源需要几分钟时间,请耐心等待,待部署成功之后便可开始使用。
1.4 向量数据库介绍
在人工智能和机器学习领域,向量数据库扮演着至关重要的角色,尤其是在处理非结构化数据,如文本、图像和音频时。
向量数据库的核心功能是将各类数据转换成向量形式,这些向量在数学上表示为高维空间中的点。每个向量捕获了数据的含义和上下文信息,使得我们可以通过计算向量之间的距离来找到相似的数据点。
第二章 大型语言模型(LLM)的基本原理
2.1 分词器
从采集数据开始,投喂给大语言模型进行训练的过程,需要将句子传递到分词器(Tokenizer ),分词器会将每个词语转换成数字表示。对于像我们后续介绍到的Transformer模型,需要确保,训练、输入、生成过程,所使用的分词器必须是统一规则的。
例子:
老 四 川 菜 馆 ,可分词为:
“老”,”四川菜馆”
“老四”,”川菜馆”
“老四川”,”菜馆”

这苹果不大好吃,可分词为:
“这苹果”,”不大好吃”
“这苹果”,”不大”,”好吃”
“这苹果不大好”,”吃”


| 分词器类型 | 分词器例子 | 优势 | 局限性 |
|---|---|---|---|
| 基于词典的分词器 | 最大正向匹配(MM)\ 最大逆向匹配(MRM) | 词典更新灵活,易于实现 | 对未知词处理不佳 |
| 基于统计的分词器 | 隐马尔可夫模型(HMM)\ 条件随机场(CRF) | 对未知词有较好处理能力 | 需要大量已标注数据 |
| 基于理解的分词器 | 语义分析分词器 | 可以理解句子含义,分词准确 | 实现复杂,计算成本高 |
| 基于机器学习的分词器 | 决策树分词器\神经网络分词器 | 可以从数据中学习分词规则 | 需要大量训练数据 |
| 子词分词器 | WordPiece分词器\Byte Pair Encoding(BPE) | 处理未知词能力强 | 可能产生大量子词单元 |
| 特定领域的分词器 | 医学分词器\法律分词器 | 包含领域特定词汇和规则 | 通用性差,仅适用于特定领域 |

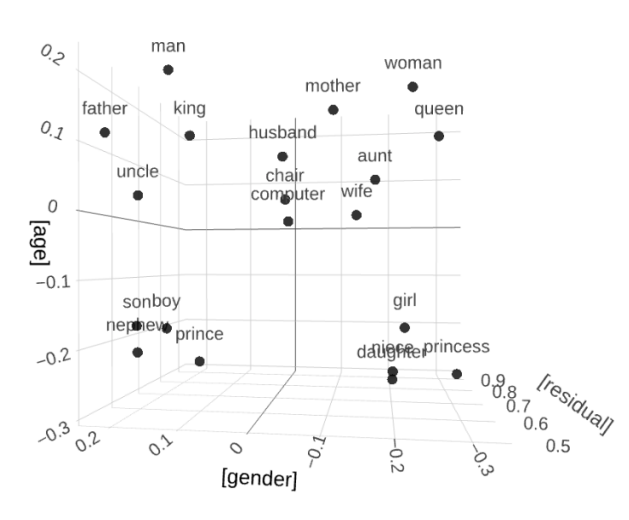
2.2 词嵌入(Word Embedding)
词嵌入就像是把词汇放进了一个大型的坐标系里,每个词都对应一个特定的点。这个坐标系是根据词的语义和用法来设计的,所以相似的词在坐标系里的位置会比较接近。比如,“猫”和“狗”在坐标系里的位置就会比较近,因为它们都是宠物的意思。
这个技术的关键在于,它不仅仅考虑了一个词本身的意思,还考虑了这个词是怎么和其他词一起出现的,也就是它的上下文。这样,即使两个词看起来意思不一样,但如果它们经常一起出现,它们在坐标系里的位置也会比较近。
举个例子,比如“银行”和“贷款”,虽然它们是两个不同的词,但因为在很多句子中它们都会一起出现,比如“我去银行申请贷款”,所以它们在坐标系里的位置就会比较近。
词嵌入的好处是,它可以帮助计算机更好地理解语言,就像我们人类理解语言一样。这样,计算机就可以更准确地完成一些任务,比如语音识别、文本分析、机器翻译等。
词嵌入的训练通常需要大量的文本数据,通过这些数据,算法可以学习到词与词之间的关系,并把它们编码到向量中。现在有很多种词嵌入的方法,比如Word2Vec、BERT等,它们都有自己的特点,但共同的目标都是更好地捕捉词的语义和上下文信息。
所以,词嵌入就是让计算机能够理解词汇背后的含义和关系的一种技术,它为计算机处理语言提供了非常重要的工具。
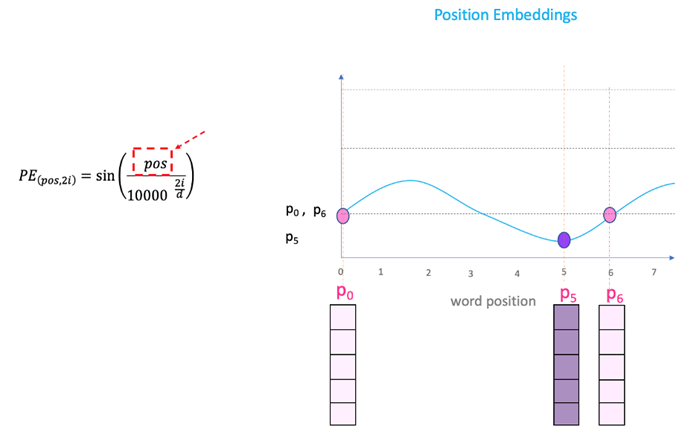
2.3 位置编码(Position Encoding)
Transformer的Position Encoding是通过将位置信息编码到嵌入向量中来完成的。
在Transformer模型中,位置编码(Positional Encoding)是一种用于给模型提供序列中各个位置的相对或绝对位置信息的方法。
这种信息对于模型理解序列中词汇的顺序和上下文关系至关重要。
一般而言,位置嵌入是通过正弦和余弦函数与位置的线性组合来构造的,并且将位置向量与词嵌入向量相加或进行某种形式的合并,以便在模型的其他部分(如自注意力机制)中使用。

2.4 Transformer模型
实时上,生成算法在很久之前就已经出现了。前几代语言模型使用了一种称为循环神经网络或RNN的架构。
RNN:循环神经网络(Recurrent Neural Network)
LSTM:长短时记忆模型(Long Short Term Memory)
GRU:门控循环单元结构(Gate Recurrent Unit)
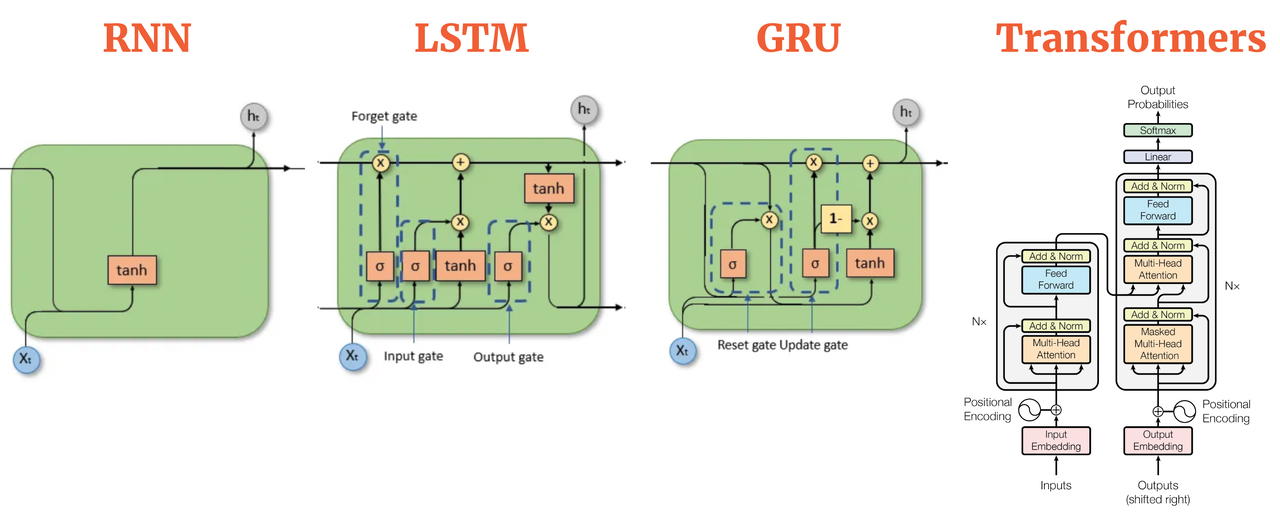
RNN虽然在当时很强大,但若要生成表现出色的任务时候需更多算力或内存量。 让我们来看一个RNN执行一个简单的下一词预测生成任务的示例。
| 效果 | 上下文长度 |
|---|---|
| ——————- 尝起来 ____。 | 短 |
| ——————- 这杯饮料尝起来 __很好__。 | 中 |
| 放坏的这杯饮料尝起来 __很好__。 | 长 |
如果模型只看到前面一句话的一部分的时候 ,预测就不可能非常好。 当你扩展 RNN 实现以便能够在文本中看到更多前面的单词时,你必须大幅扩展模型使用的资源。
尽管你将模型变得更大,但它仍然没有看到足够的输入,来做出良好的预测。为了成功预测下一个单词, 模型需要看到的不仅仅是前几个单词。 模型需要理解整句话甚至整个文档。
而且这里的问题是语言很复杂。在许多语言中,一个词可以有多种含义。这些是同音异义词。
以这句话为例, “意思意思是什么意思?”。

在2017年,在谷歌和多伦多大学发表这篇论文《注意力就是你所需要的》之后, 一切都变了,Transformer直译过来是变形金刚。Transformer架构已经到来。 这种新颖的方法开启了我们今天看到的生成式人工智能的进步。
它可以有效地扩展以使用多核 GPU,它可以并行处理输入数据,利用更大的训练数据集,而且至关重要的是,它能够学会注意正在处理的单词的含义。
Transformer是一种基于多头注意力机制的深度学习架构,由谷歌和多伦多大学于2017年提出,并在《Attention is All You Need》论文中详细描述。该架构在生成人工智能领域取得了显著进展,引领了今天许多领域的发展。


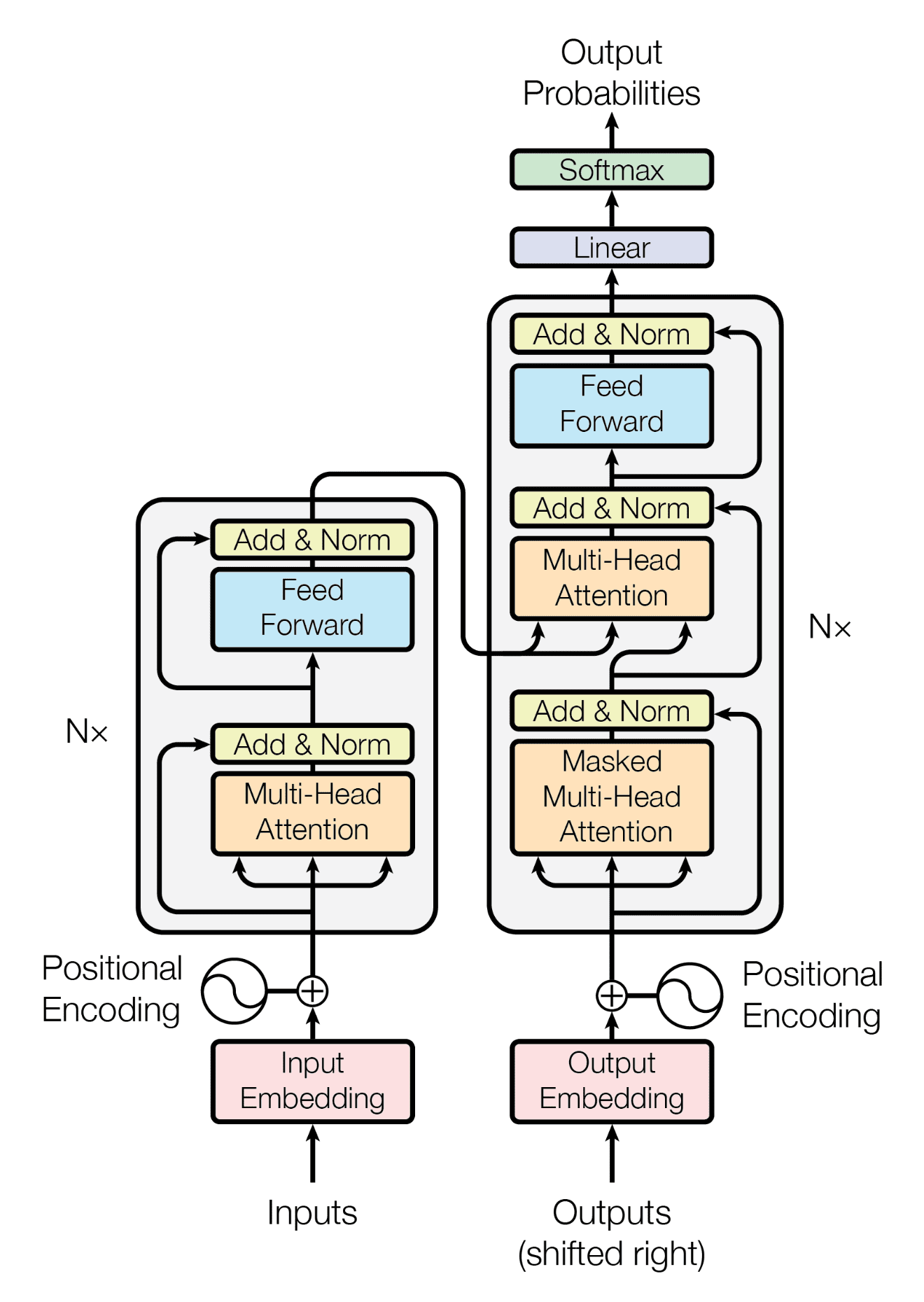
如下图所示,当输入这句话到大语言模型的时候:”many people dislike steve jobs, while acknowledging his genius”,每一个单词就会按照相关性找到其它单词,无论该单词在那个位置。可以看到每个单词之间的关系是由权重来决定的。这些注意力权重是在大语言模型训练时确定的。

2.5 什么是Transformer的多头注意力机制?
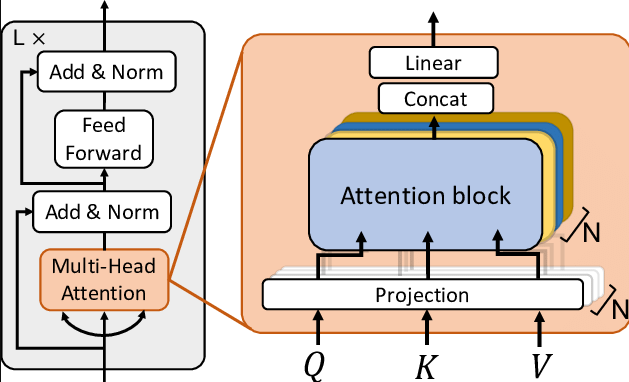
Transformer 中的多头注意力机制(Multi-Head Attention)是一种注意力分配机制,它允许模型在处理输入序列时同时关注多个不同的表示子空间。
这种机制在 Transformer 模型中起到了关键作用,使得模型能够有效地捕捉序列中的复杂依赖关系。
多头注意力机制的核心思想是将注意力分为多个“头”,每个头关注输入序列的不同部分。这些头是并行工作的,每个头都有自己的查询(Query)、键(Key)和值(Value)矩阵。
通过对这些矩阵进行线性变换,可以得到每个头对应的注意力权重。然后,将权重与值矩阵相乘,得到加权的输出值,最后将所有头的输出值进行拼接,得到最终的输出。
用一张图来更进一步理解:
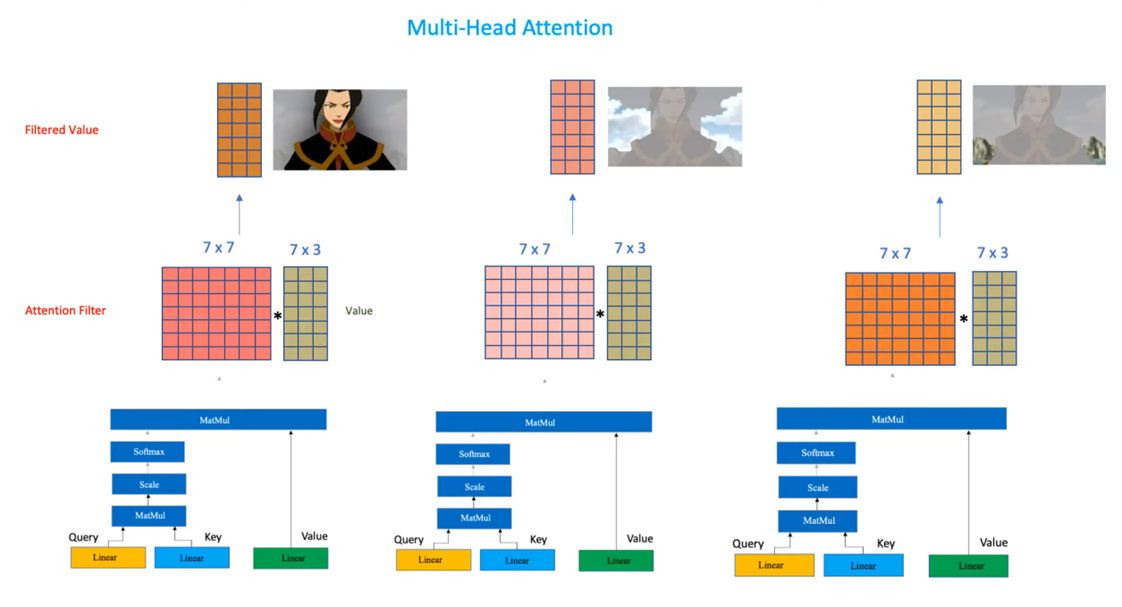
2.6 Transformer的模型分类
2.6.1 序列到序列模型
seq2seq模型,简单来说,就是一个用来处理像文本或者时间序列这类序列数据的深度学习模型。比如机器翻译、语音识别、文本摘要这些任务,它都能搞定。
这个模型主要分成两大部分:编码器和解码器。编码器的作用是接收输入的序列,然后把它转化成一个固定长度的向量,这个向量就包含了输入序列的所有信息。解码器呢,就是用这个向量来生成我们想要的输出序列。它一次生成一个元素,然后把这些元素连起来,形成我们想要的序列。
在训练这个模型的时候,我们一般会用一个叫“教师强制”的方法,就是让模型每次都接收真实的序列数据,这样它就能慢慢学会怎么生成正确的序列了。等到模型训练好了,我们让它自己生成序列,这时候它就不需要外界输入了,而是利用自己之前学到的知识来生成序列。
此外,还有一些改进的版本,比如加入注意力机制,这个机制能让模型更关注输入序列中重要的部分,从而提高生成的质量。
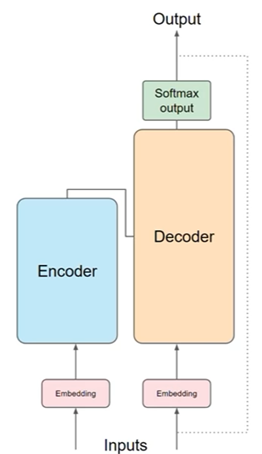
用途:翻译(将德语翻译成英语)
2.6.2 只有编码器模型
这通常被称为“编码器-解码器”(Encoder-Decoder)模型或者“序列编码器”(Sequence Encoder)模型。在这种情况下,你只保留了Seq2Seq模型中的编码器部分,用来处理输入序列,并将其转换为上下文向量。
这种简化模型的用途通常有限,因为它只能编码输入序列,而不能生成输出序列。然而,在某些情况下,这种模型还是有用的,比如:
- 序列分类:你可以使用编码器来提取序列的特征表示,然后将这些特征输入到一个分类器中,用于对序列进行分类。
- 序列标注:在序列标注任务中,编码器可以用来生成每个时间步的特征表示,然后这些特征可以用来预测序列中每个时间步的标签。
- 上下文感知的嵌入:编码器可以用来生成序列的上下文感知嵌入,这些嵌入可以用于其他下游任务,如推荐系统或者序列相似性分析。
- 对话系统:在对话系统中,编码器可以用来理解用户的输入,然后根据这个理解生成响应。
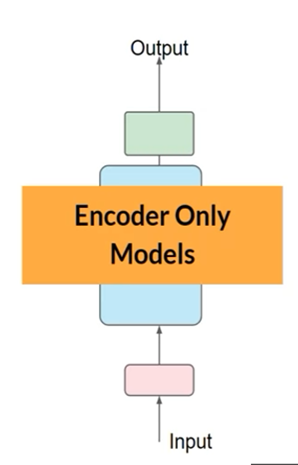
用途:适用于分类任务(情感分析)BERT就是一个很好用的仅有编码器的模型
2.6.3 只有解码器模型
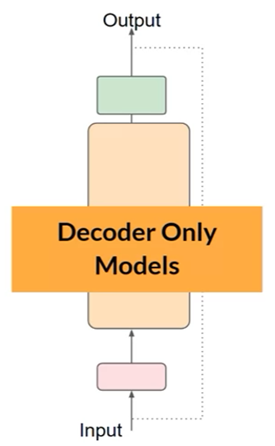
用途:适用于生成文本,是最常用的模型之一。例如GPT、Llama等等
2.7 提示词工程师工作内容
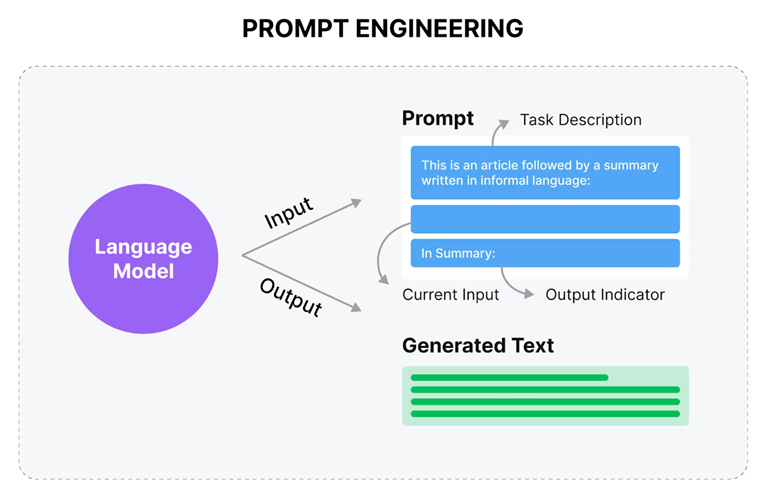
在使用语言模型时,我们通常将输入的文本称为“提示”(prompt)。
而模型根据提示生成文本的过程被称作“推理”(inference)。
模型输出的文本结果则被称为“完成”(completion)。
在模型进行推理时,所能考虑的提示内容的全部范围,或者是模型可以访问的内存空间,被定义为“上下文窗口”(context window)。
在实际应用中,我们可能会遇到模型初次生成的文本并不完全符合预期的情况。这时候,可能需要我们多次调整和优化提示的语言表达或编写方式,以便更好地引导模型生成我们想要的文本结果。这个过程涉及到的技术活动,我们称之为“提示工程”(prompt engineering)。它是建立和改进有效提示的关键步骤,对于提升模型生成文本的质量和效果至关重要。
第三章 大语言模型本地化搭建
3.1 ChatGLM3-6B部署
3.1.1 硬件环境
最低要求:
为了能够流畅运行 Int4 版本的 ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 8GB
显存: >= 5GB(1060 6GB,2060 6GB)
为了能够流畅运行 FP16 版本的,ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 16GB
显存: >= 13GB(4080 16GB)
3.1.2 软件要求
| 所需软件 | 版本 |
|---|---|
| Conda | conda3 |
| python | 版本推荐 3.10.12 |
| transformers | 版本推荐 4.30.2 |
| torch | 推荐使用 2.0 及以上的版本 |
Conda安装:
Conda是一个开源的软件包管理系统和环境管理系统,主要用于在Linux、Windows和macOS上管理Python包和它们的依赖项。它像一个虚拟环境,可以让用户在不同环境中安装和使用不同的软件包,而无需担心版本冲突问题。Conda适用于Python的多个版本,并附带大量常用的数据科学包。
1 | wget -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh |
Cuda安装:

CUDA(Compute Unified Device Architecture)是由NVIDIA公司开发的一个并行计算平台和编程模型。它允许开发者使用NVIDIA的GPU(图形处理器)进行高性能计算。
CUDA提供了一系列的API和工具,使得开发者可以用C、C++和Fortran等编程语言来编写代码,这些代码可以在GPU上并行执行,从而加速计算密集型任务,比如科学计算、数据分析、机器学习和深度学习等。
1 | wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin |
设置环境变量:
1 | echo -e "export PATH=/usr/local/cuda/bin:\$PATH\n\ |
安装Cudnn:

CUDA Deep Neural Network(cuDNN)是NVIDIA公司开发的一个开源库,专为深度神经网络设计,可以在NVIDIA的GPU上提供高性能的数值计算能力。cuDNN优化了深度学习算法中的卷积神经网络(CNN)和多层感知器(MLP)等操作的执行速度,使得神经网络模型的训练和推理能够在GPU上高效运行。
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive
1 | uname -m && cat /etc/*release |
验证安装:
1 | sudo apt-get install g++ freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libglu1-mesa libglu1-mesa-dev -y |
创建Python虚拟环境:
1 | conda create --name ChatGLM3env python=3.10.12 |
在Python虚拟环境中安装依赖:
1 | conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y |
在/root目录,克隆ChatGLM3:
1 | apt install git-lfs |
在/root目录,克隆模型:
1 | apt install git-lfs |
启动方式一:命令行模式
1 | cd /root/ChatGLM3/basic_demo |
启动方式二:免开防火墙
开放Gradio外部链接:
1 | wget -c https://cdn-media.huggingface.co/frpc-gradio-0.2/frpc_linux_amd64 |
若要开放外部访问端口,需要编辑web_demo_gradio.py文件的最底部,修改share参数为True:
1 | vim web_demo_gradio.py |
启动:
1 | cd /root/ChatGLM3/basic_demo |
启动方式三:需要开放阿里云安全组8501端口
1 | cd /root/ChatGLM3/basic_demo |
中文词嵌入模型:
BAAI General Embedding是北京智源人工智能研究院开源的一系列embedding大模型,支持中文和英文的embedding。效果很好,重要的是免费商用授权!
BAAI General Embedding - large - zh是其中文版本,输入序列512,输出维度1024
1 | git clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh.git |
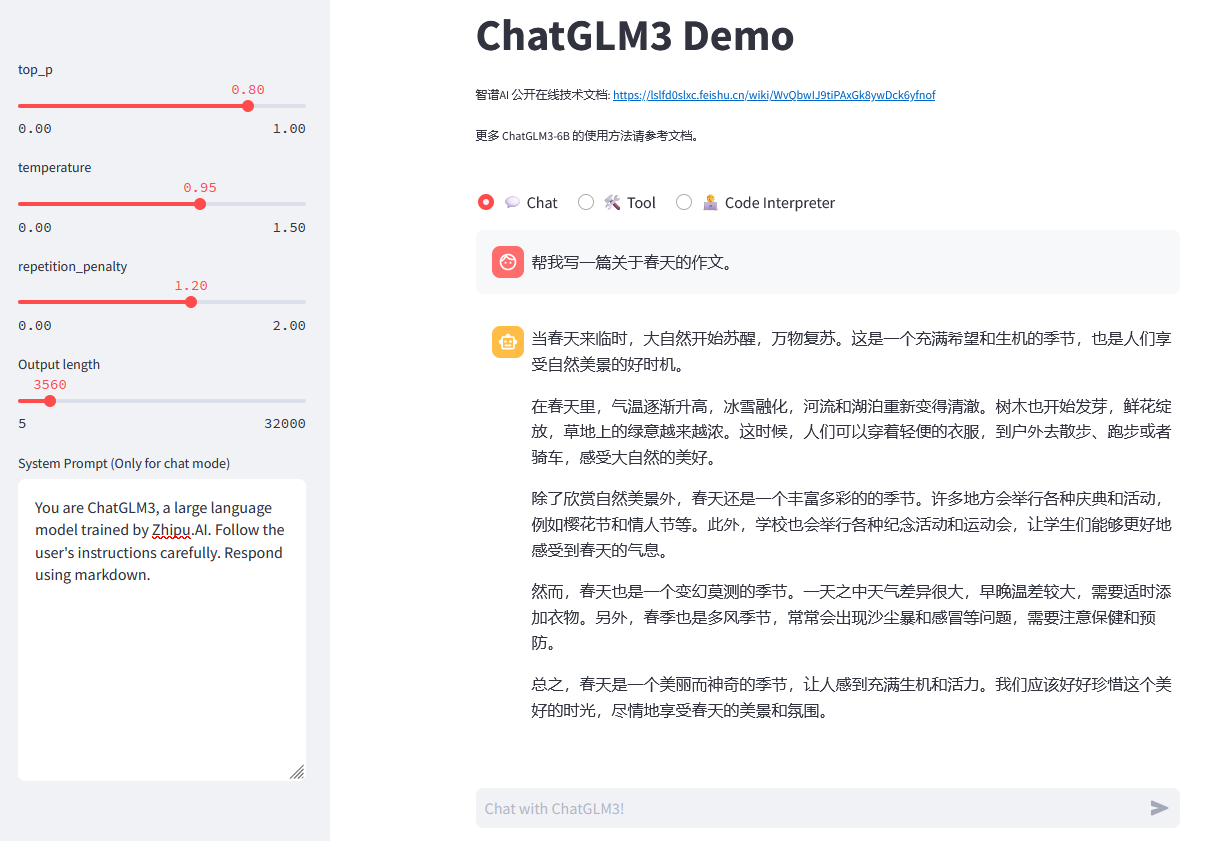
3.2 ChatGLM3-6B体验演示
3.3 ChatGLM3-6B接口调用演示
1 | from langchain.chains import LLMChain |
第四章 向量数据库ChromaDB介绍
4.1 ChromaDB安装
在本教程中,我们将使用 ChromaDB 的客户端版本。客户端版本是内存数据库,这意味着它不需要像基于服务器的数据库那样进行任何额外的设置或配置。它非常适合学习和测试目的,因为它允许您快速轻松地试验 ChromaDB 的功能。但是,请记住,由于它位于内存中,因此当 Python 脚本完成运行时,存储在客户端中的数据将会丢失。
安装向量数据库
1 | pip install chromadb |
1 | import chromadb |
4.2 函数介绍
4.2.1 客户端类型
ChromaDB提供了不同的客户端类型以适应不同的使用场景。
| 客户端类型 | 描述 | 用途 |
|---|---|---|
| EphemeralClient | 临时客户端,会话结束后自动断开连接。 | 用于不需要持久连接的场景,例如简单的数据插入或查询。 |
| PersistentClient | 持久客户端,保持连接状态直到显式断开。 | 用于需要长时间运行的应用程序,可以复用连接以提高效率。 |
| HttpClient | HTTP 客户端,通过 HTTP 协议与 ChromaDB 通信。 | 用于可以通过 HTTP 请求访问 ChromaDB 的场景。 |
| Client | 通用的客户端接口,可以是 EphemeralClient 或 PersistentClient。 | 用于不关心客户端类型的场景,可以根据需要自动选择合适的客户端。 |
4.2.2 客户端方法
| 函数 | 功能 | 用途 |
|---|---|---|
| heartbeat | 发送心跳包以保持连接活跃。 | 用于保持客户端与 ChromaDB 的连接活跃。 |
| list_collections | 列出所有向量集合。 | 用于获取数据库中所有向量集合的列表。 |
| create_collection | 创建一个新的向量集合。 | 用于创建新的向量集合以存储向量数据。 |
| get_collection | 获取指定向量集合的详细信息。 | 用于获取特定向量集合的信息。 |
| get_or_create_collection | 获取指定向量集合,如果不存在则创建它。 | 用于确保向量集合存在,并返回它的引用。 |
| delete_collection | 删除指定的向量集合。 | 用于删除不再需要的向量集合。 |
| reset | 重置客户端状态。 | 用于重置客户端的状态,例如清除缓存。 |
| get_version | 获取 ChromaDB 的版本信息。 | 用于获取当前运行的 ChromaDB 版本。 |
| get_settings | 获取 ChromaDB 的设置信息。 | 用于获取 ChromaDB 的配置设置。 |
4.2.3 集成对象
| 函数 | 功能 | 用途 |
|---|---|---|
| count | 返回指定向量集合中向量的数量。 | 用于统计向量集合中元素的数量。 |
| add | 向指定向量集合中添加一个或多个向量。 | 用于向集合中添加新的向量数据。 |
| get | 获取指定向量的值。 | 用于获取一个向量对应的值。 |
| peek | 查看指定向量的值,但不改变其缓存状态。 | 用于查看向量的值,但不影响该值在数据库中的缓存时效。 |
| query | 执行一个查询,返回满足条件的向量及其对应的值。 | 用于在向量集合中查询满足特定条件的向量。 |
| modify | 修改指定向量的值。 | 用于修改一个已经存在的向量的值。 |
| update | 更新指定向量的值,如果向量不存在,则创建向量。 | 用于更新一个向量的值,如果向量不存在,则创建新的向量。 |
| upsert | 更新指定向量的值,如果向量不存在,则创建向量。 | 用于更新一个向量的值,如果向量不存在,则创建新的向量。 |
| delete | 删除指定向量。 | 用于删除一个向量以及其对应的值。 |
4.3 集合的增删改查
1 | import chromadb |
4.4 添加文档到ChromaDB
4.4.1 添加原始文档
1 | import chromadb |
4.4.2 添加文档关联
1 | import chromadb |
4.4.3 添加嵌入和元数据
1 | import chromadb |
4.5 查询集合
4.5.1 查询嵌入
1 | import chromadb |
4.5.2 查询文本
1 | import chromadb |
4.5.3 通过ID检索
1 | import chromadb |
4.5.4 通过文本检索数据
1 | import chromadb |
4.5.5 通过查询条件检索数据
1 | import chromadb |
4.6 更新集合中的数据
4.6.1 更新属性
1 | import chromadb |
4.6.2 更新插入操作
1 | import chromadb |
4.7 删除集合中的数据
4.7.1 按ID删除
1 | import chromadb |
4.7.2 按条件删除
1 | import chromadb |
4.8 使用嵌入函数
4.8.1 使用OpenAI嵌入函数
需要确保本机已经安装openai的python包。
1 | pip install openai |
1 | import chromadb |
4.8.2 自定义嵌入函数
1 | import chromadb |
4.9 向量数据库与langchain应用
1 | from langchain.text_splitter import CharacterTextSplitter |
第五章 大语言模型微调 - LangChain
5.1 LangChain原理
5.1.1 微调的目的
- 学习更统一的回复,学习关注的信息,让模型更善于交谈
- 获取新知识,增加对新的概念以及了解,更正旧的不正确信息
- 二者兼备
5.1.2 微调常见任务
1、更多的输入,更简洁的答案
例如:阅读、提取关键词、主题、摘要等等
2、更少的输入,更多的输入
例如:写作、聊天、解决问题、写代码等等
3、判断好坏
例如:针对电影评论的判别、针对美食的判别。给出具体答案。
5.1.3 微调前的数据要求
数据是决定微调效果的重点。
| 要求 | 解释 |
|---|---|
| 质量要求 | 高质量数据比低质量数据更重要 |
| 数据多面性 | 多方数据比单方数据更好(即学习举一反三的能力) |
| 数据来源 | 人工编写比机器生成更加精准 |
| 数据广泛性 | 学习更多的数据比学习更少的数据能让模型知识更广泛 |
5.2 Langchain介绍以及安装
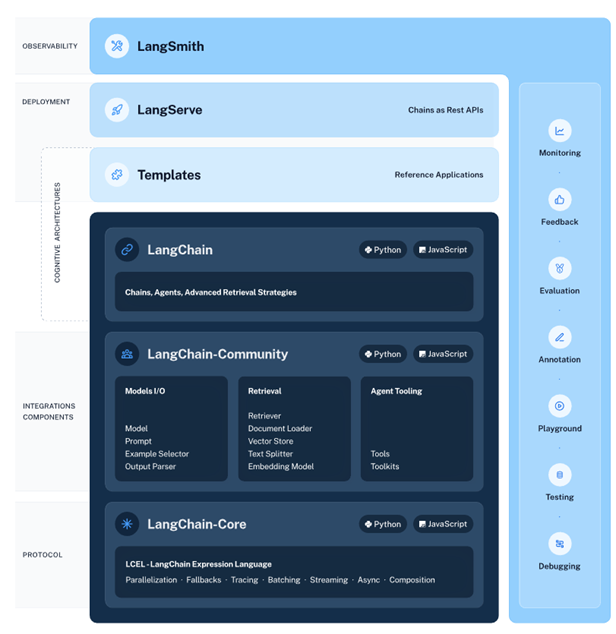
LangChain是一个用于开发由语言模型支持的应用程序的框架。
它主要由以下几个部分组成:
模型集成:支持多种预训练语言模型,包括用于理解和生成文本的大模型。
对话和交互:集成了对话模型,用于与用户进行交互。
文本嵌入:提供文本到向量的转换,便于进行相似性分析或检索。
提示词和模板:提供预设的提示词模板,帮助用户构建任务指令。
输出转换:允许用户自定义模型的输出格式。
索引和检索:提供文档索引和向量数据库,方便快速检索信息。
链式操作:支持将多个模型和任务串联起来,形成更复杂的处理流程。
代理和多任务:允许用户同时管理和运行多个模型或任务。
PIP安装:
1 | pip install langchain |
Conda安装:
1 | conda install langchain -c conda-forge |
LangSmith的作用是检查链或代理内部的运行情况,但LangSmith不是必需的,若要使用LangSmith则需要注册:https://smith.langchain.com/
5.3 LangChain与ChatGLM3-6B集成
1 | from langchain.chains import LLMChain |
5.4 LangChain与Azure OpenAI集成
以下是LangChain与Azure OpanAI集成的代码示例
1 | import os |
由于Azure OpenAI的申请需要企业认证,过程较为麻烦,因此改为OpenAI对接:https://platform.openai.com/docs/overview
5.5 LangChain例子1 - 基础使用
1 | from langchain.chat_models import ChatOpenAI |
过程:

输出结果:’为什么企鹅不会用电脑?因为它们的手指头太粗大,按不准键盘。’
5.6 LangChain例子2 - 内存检索
第一步:创建一个RunnableParallel具有两个条目的对象。
第一个条目context将包括检索器获取的文档结果。
第二个条目question将包含用户的原始问题。为了传递这个问题,我们使用 RunnablePassthrough复制此条目。
第二步:将上述步骤中的字典提供给prompt组件。然后,它获取用户输入question以及检索到的文档,context以构造提示并输出 PromptValue。
第三步:该model组件采用生成的提示,并传递到 OpenAI LLM 模型进行评估。模型生成的输出是一个ChatMessage对象。
第四步:最后,该output_parser组件接收 aChatMessage并将其转换为 Python 字符串,该字符串从 invoke 方法返回。
1 | !pip install pydantic==1.10.13 |
1 | from langchain.chat_models import ChatOpenAI |
过程:

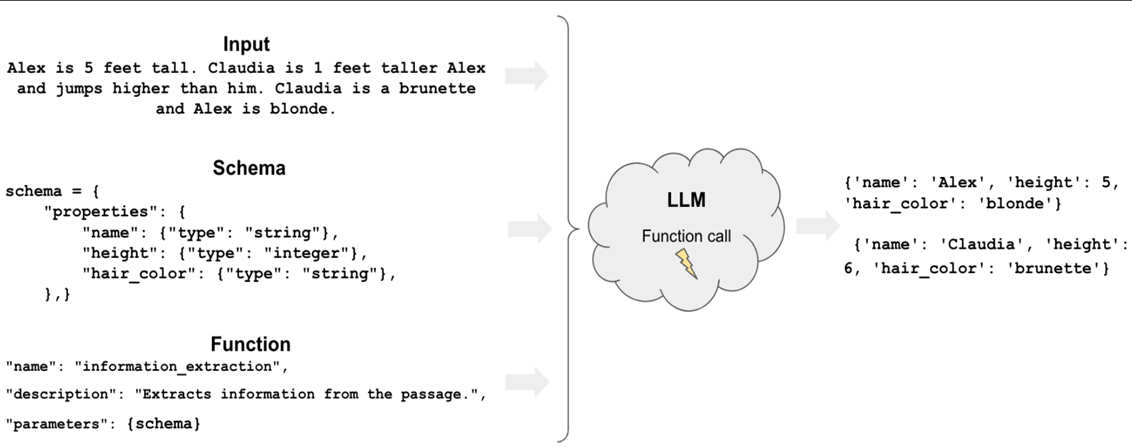
5.7 LangChain例子3 - 信息提取
信息提取:
1 | from langchain.chains import create_extraction_chain |
输出结果:
1 | {'input': '去年小明15岁,今年身高130cm。今年小红6岁,身高140, 我需要json格式', |
5.8 LangChain例子4 - 与数据库结合
1 | from langchain.chat_models import ChatOpenAI |
创建sql语句的工具
1 | from langchain.chat_models import ChatOpenAI |
5.7 其它微调框架
5.7.1 lamini微调小例子
官方代码:https://github.com/lamini-ai/lamini
Lamini是领先的大语言模型微调平台。可以使每个企业和开发人员都能轻松构建定制的私有模型:比任何一般的大语言模型更容易、更快、性能更高。
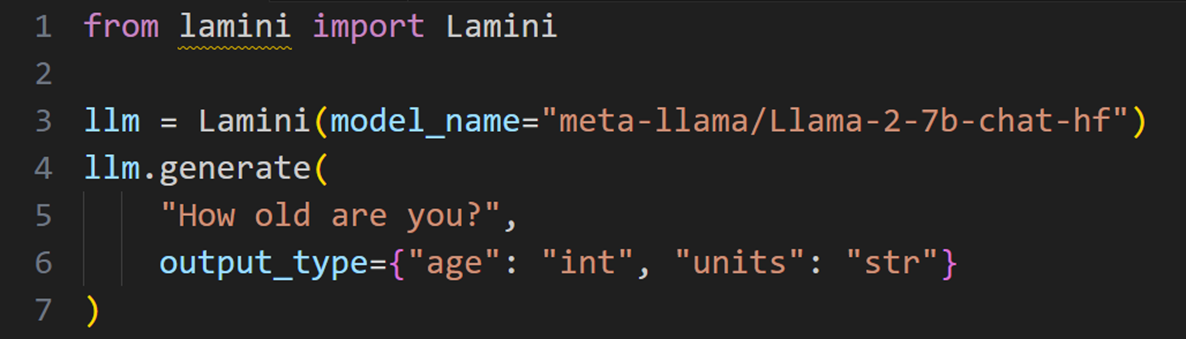
输出:{
‘age’: 25,
‘units’: ‘years’
}
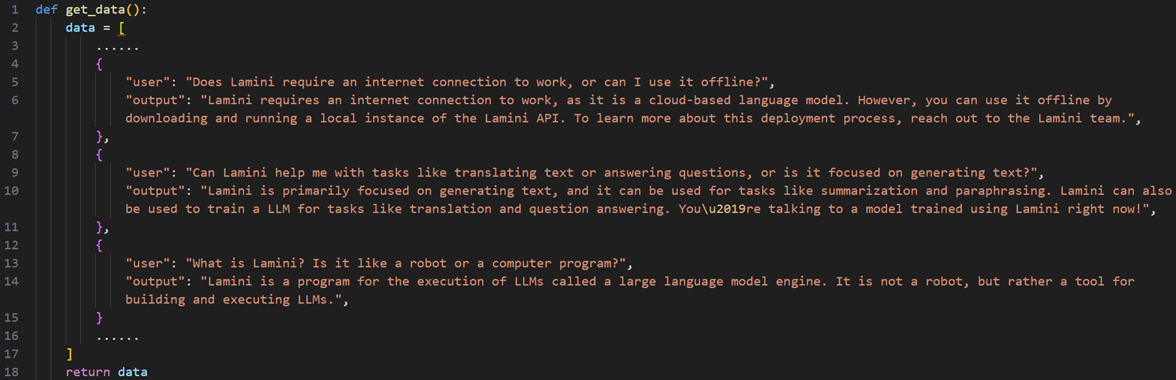
5.7.2 lamini训练小例子
准备数据:
第六章 大语言模型微调 - PEFT
6.1 提示词的局限性
1、上下文窗口长度有限。
2、小模型无法正常通过上下文学习
大语言模型从零开始训练,通常需要巨量的数据:GB级别、TB级别、PB级别,训练完成后的模型称为预训练模型。
微调大语言模型
微调:需要基于预训练模型进行针对性的、特定一个或多个问题对模型进行二次训练。
6.2 数据准备
在训练前需要准备的训练数据格式为:问题以及标准答案。
比如分类任务:
问题:《功夫》这部电影怎么样?标准答案:好
问题:坏苹果好吃吗?标准答案:不好
比如总结任务:
问题:JS通常是JavaScript的缩写,它是一种高级的、解释型编程语言,广泛用于网页开发中,用于实现网页的交互效果和动态内容。JavaScript最初由Netscape公司的 Brendan Eich 在1995年设计,后来得到了广泛的标准化和 adoption,成为Web开发不可或缺的一部分。
标准答案:JavaScript(简称JS)是一种高级编程语言,主要用于网页开发以增加交互性和动态内容。它在1995年由Netscape公司的Brendan Eich设计,并逐渐被标准化和广泛采用,成为Web开发中不可或缺的技术之一。
比如翻译任务:
问题:请将“外卖”翻译成英文。 标准答案:Delivery service (food delivery)
问题:请将“电子商务”翻译成英文。 标准答案:E-commerce (Electronic Commerce)
问题:请将“移动支付”翻译成英文。 标准答案:Mobile payment
问题:请将“共享单车”翻译成英文。 标准答案:Shared bicycles (bike-sharing)
通常需要将数据划分成:训练集、验证集、测试集
6.3 微调大语言模型分为两种方式:
6.3.1 全量微调
全量微调需要更新模型的所有参数。
6.3.2 PEFT微调
Lora微调:LoRA(Low-Rank Adaptation)
6.4 微调的过程:
训练过程会将训练集中的数据逐个取出,交给预训练模型进行推理。推理后通过交叉熵计算损失值。
通常微调一个任务仅需要500~1000个相关的问题即可。
6.5 灾难性遗忘
虽然微调可以让特定任务的问题回答得更加准确,但是亦会带来另外一个问题,那就是微调训练过程中影响了原本的参数,导致模型遗忘原来的信息。从而导致推理其它任务的效果下降。
那么如何避免灾难性遗忘呢?
1、也许你不需要微调也能通过提示工程完成你的任务
2、多任务同时微调,同时针对不同的任务进行微调,如分类、翻译、总结、信息提取。
3、通过参数高效微调PEFT的方式如Lora,进行微调
FLAN(Fine-tuned Language net),是谷歌研究开发的一种先进的自然语言处理模型。许多开发者喜欢使用该模型进行微调,但是遗憾的是它只支持英文。
6.6 模型评估指标
以下是常用的模型评估指标及其定义和公式:
6.6.1 准确率(Accuracy)
定义:正确预测的样本数占总样本数的比例。
公式:
$$
\text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}}
$$
6.6.2 精确率(Precision)也称为查准率
- 定义:被预测为正例的样本中,实际为正例的比例。
- 公式:
$$
\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}召回率(Recall)**,也称为查全率
$$
6.6.3 召回率(Recall)也称为查全率
定义:实际为正例的样本中,被正确预测为正例的比例。
公式:
$$
\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}
$$
6.6.4 F1分数(F1-Score)
- 定义:精确率和召回率的调和平均值,用于衡量模型的精确性和稳健性。
- 公式:
$$
\text{F1-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}
$$
6.6.5 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
定义:主要用于自动文摘和机器翻译的评价指标,衡量系统的摘要与原文的相似度。
ROUGE-1指标例子1:
人类生成的标准:The cat sat on the mat.
大语言模型推理:The mouse watched the cat on the mat.
| 公式 | 结果 | 备注 |
|---|---|---|
| $$\text{ROUGE-1 Recall}=\frac{\text{unigram matches}}{\text{unigrams in reference}}$$ | $\frac{3}{4} = 0.75$ | ROUGE-1 召回率 |
| $$\text{ROUGE-1 Precision}=\frac{\text{unigram matches}}{\text{unigrams in output}}$$ | $\frac{3}{5} = 0.6$ | ROUGE-1 精确率 |
| $$\text{ROUGE-1 F1}=2\frac{\text{precision x recall}}{\text{precision + recall}}$$ | $2\frac{0.6 \times 0.75}{0.6 + 0.75} \approx 0.68$ | ROUGE-1 F1分数 |
ROUGE-1指标作弊例子2:
人类生成的标准:It is cold outside.
大语言模型推理:cold,cold,cold,cold.
| 公式 | 结果 | 备注 |
|---|---|---|
| $$\text{ROUGE-1 Recall}=\frac{\text{unigram matches}}{\text{unigrams in reference}}$$ | $\frac{4}{4} = 1.0$ | ROUGE-1 召回率 |
| $$\text{ROUGE-1 Precision}=\frac{\text{unigram matches}}{\text{unigrams in output}}$$ | $\frac{4}{4} = 1.0$ | ROUGE-1 精确率 |
| $$\text{ROUGE-1 F1}=2\frac{\text{precision x recall}}{\text{precision + recall}}$$ | $2\frac{1.0 \times 1.0}{1.0 + 1.0} = 1.0$ | ROUGE-1 F1分数 |
ROUGE-1指标反作弊例子3:
人类生成的标准:It is cold outside.
大语言模型推理:cold,cold,cold,cold.
| 公式 | 结果 | 备注 |
|---|---|---|
| $$\text{ROUGE-1 Recall}=\frac{\text{unigram matches}}{\text{unigrams in reference}}$$ | $\frac{4}{4} = 1.0$ | ROUGE-1 召回率 |
| $$\text{ROUGE-1 Precision改版}=\frac{\text{clip(unigram matches)}}{\text{unigrams in output}}$$ | $\frac{1}{4} = 0.25$ | ROUGE-1 精确率 |
| $$\text{ROUGE-1 F1改版}=2\frac{\text{clip(precision x recall)}}{\text{precision + recall}}$$ | $2\frac{1.0 \times 0.25}{1.0 + 0.25} = 0.4$ | ROUGE-1 F1分数 |
ROUGE-2指标例子4:
人类生成的标准:”The sun sets in the west, and the moon rises in the east.”
模型推理文本: “The sun dips in the direction of the setting west, as the moon climbs in the opposite direction from the rising east.”
| 公式 | 结果 | 备注 |
|---|---|---|
| $$\text{ROUGE-2 Recall}=\frac{\text{bigrams matches}}{\text{bigrams in reference}}$$ | $\frac{3}{8} = 0.375$ | ROUGE-2 召回率 |
| $$\text{ROUGE-2 Precision}=\frac{\text{bigrams matches}}{\text{bigrams in output}}$$ | $\frac{3}{10} = 0.3$ | ROUGE-2 精确率 |
| $$\text{ROUGE-2 F1}=2\frac{\text{precision x recall}}{\text{precision + recall}}$$ | $2\frac{0.3 \times 0.375}{0.3 + 0.375} \approx 0.328$ | ROUGE-2 F1分数 |
ROUGE-L指标例子5
参考文本(人类生成):”It is cold outside.”
模型推理文本: “It is very cold outside.”
| 公式 | 结果 | 备注 |
|---|---|---|
| $$\text{ROUGE-L Recall}=\frac{\text{LCS length}}{\text{reference text length}}$$ | $\frac{9}{10} = 0.9$ | ROUGE-L 召回率 |
| $$\text{ROUGE-L Precision}=\frac{\text{LCS length}}{\text{system text length}}$$ | $\frac{9}{11} \approx 0.818$ | ROUGE-L 精确率 |
| $$\text{ROUGE-L F1}=2\frac{\text{precision x recall}}{\text{precision + recall}}$$ | $2\frac{0.9 \times 0.818}{0.9 + 0.818} \approx 0.863$ | ROUGE-L F1分数 |
- BLEU SCORE
定义:一个用于评估机器翻译质量的指标,基于与参考翻译的相似度来计算。
其他常用的评估指标包括:
- MSE(Mean Squared Error):用于回归问题的平均平方误差,衡量预测值与真实值之间的差异。
- MAE(Mean Absolute Error):用于回归问题的平均绝对误差,也是衡量预测值与真实值差异的一种指标。
- ROC曲线(Receiver Operating Characteristic Curve)和AUC(Area Under ROC Curve):用于二分类问题,ROC曲线展示的是分类阈值变化时,真正例率(TPR)和假正例率(FPR)的关系,AUC则是ROC曲线下的面积,衡量模型的总体性能。
- Precision-Recall Curve:展示的是精确率和召回率的关系曲线,用于评估模型对不同类别的重要性。
6.1 大型语言模型的调优技巧Fine-Tune
大型语言模型的调优技巧Fine-Tuning(简称FT)是一种在自然语言处理(NLP)中常用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。以下是Fine-Tuning的一些常见技巧:
- 数据准备:为Fine-Tuning准备高质量的数据集,包括训练集、验证集和测试集。确保数据集与任务相关且具有代表性。
- 模型选择:选择一个与任务相关的预训练模型。例如,GPT-3或BERT模型。
- 参数设置:在Fine-Tuning过程中,可以根据任务需求调整模型的超参数,如学习率、批次大小、迭代次数等。
- 冻结与解冻:在Fine-Tuning过程中,可以选择冻结预训练模型的部分层,只训练与任务最相关的层。这有助于提高训练效率并防止过拟合。
- 早期停止:在训练过程中,定期评估模型在验证集上的性能。当性能不再提升时,可以停止训练以避免过拟合。
- 正则化:在Fine-Tuning过程中,可以采用正则化技术(如dropout、权重衰减等)来防止过拟合。
- 多任务学习:在Fine-Tuning过程中,可以考虑将多个任务的数据集混合在一起进行训练。这有助于提高模型的泛化能力。
- 动态学习率:在Fine-Tuning过程中,可以设置动态学习率,使模型在不同阶段采用不同的学习率。
- 注意力机制:利用预训练模型中的注意力机制,可以根据任务需求调整注意力权重,使模型更加关注与任务相关的信息。
- Prompt Tuning:在输入数据前添加与任务相关的提示(prompt),引导模型生成所需的输出。这种方法可以进一步提高模型在特定任务上的性能。
6.2 全量微调介绍
大语言模型全量微调(Full Fine-tuning of Large Language Models)是指对预训练的大型语言模型(如GPT-3、BERT等)进行微调的过程,以适应特定的下游任务。在这个过程中,模型的所有参数都被重新训练,以便更好地适应该任务。全量微调通常涉及到大量的计算资源和时间,因为需要对模型的数十亿个参数进行调整。
PEFT(Parameter-Efficient Fine-tuning)是一种参数效率更高的微调方法,它通过只微调模型的一部分参数来减少计算资源的需求。PEFT的核心思想是冻结预训练模型的大部分权重,只训练与特定任务最相关的部分。这种方法通常涉及到在模型的输入层或输出层添加额外的可训练层,或者通过低秩分解等技术来减少需要微调的参数数量。
区别:
- 参数调整:在全量微调中,模型的所有参数都会被调整;而在PEFT中,只有部分参数被调整,通常是那些与任务最相关的参数。
- 计算资源:全量微调通常需要更多的计算资源,因为它涉及到调整更多的参数;PEFT则需要较少的计算资源,因为它只调整少量的参数。
- 时间:全量微调可能需要更长的时间来完成,因为它需要对更多的参数进行训练;PEFT通常可以更快地完成,因为它只需要训练少量的参数。
- 性能:全量微调可能会在特定任务上提供更高的性能,因为它对模型的所有参数进行了调整;PEFT的性能可能略低于全量微调,但它提供了一种更高效的微调方法,可以在资源有限的情况下使用。
6.3 Lora微调原理
大语言模型微调(Fine-Tuning, FT)是一种常见的机器学习技术,用于将预训练的语言模型适应于特定的下游任务。微调的过程通常包括在任务特定的数据集上对模型进行进一步的训练,以便模型能够学习到与任务相关的特定知识。
然而,微调大型语言模型(如GPT-3)可能会遇到计算资源不足和训练时间过长的问题。为了解决这些问题,研究者提出了多种参数效率的微调方法,其中一种是LoRA(Low-Rank Adaptation)。
LoRA的微调原理基于以下几个关键点:
- 低秩分解:LoRA通过将预训练模型的权重矩阵分解为低秩的矩阵乘积,来减少需要微调的参数数量。这种分解通常涉及到奇异值分解(SVD)或类似的数学技术。
- 参数效率:通过低秩分解,LoRA能够将原始模型的权重矩阵替换为较小的矩阵,从而减少了微调过程中需要更新的参数数量。这大大降低了计算成本和训练时间。
- 适应性:LoRA通过在低秩分解的基础上添加一些额外的参数(如旁路矩阵)来模拟全参数微调的效果。这些额外参数的学习可以捕捉到任务特定的特征,同时保持模型的整体结构。
- 训练过程:在微调过程中,LoRA方法只更新分解后的低秩矩阵和额外参数,而冻结了原始预训练模型的其余部分。这使得训练过程更加高效,因为只有一小部分参数需要被调整。
- 性能:尽管LoRA减少了微调的参数数量,但它仍然能够保持或接近全参数微调的性能。这是因为低秩分解能够保留原始模型的大部分重要信息,同时允许模型适应新的任务。
LoRA方法的出现显著提高了大型语言模型微调的效率,使得在资源有限的情况下也能够有效地适应新任务。这种方法已经在多个NLP任务中得到了应用,并取得了良好的效果。
6.4 Lora微调实验
参考:https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e
第七章 应用实践
7.1 需求分析
项目名称:智能客服系统
项目目标:
- 提供自动化的客户服务,减轻人工客服负担。
- 提高客户服务效率,减少等待时间。
- 提升客户满意度,准确快速解答问题。
- 收集分析客户反馈,改进产品服务。
功能需求:
- 多接入方式:支持网站、移动应用、电话等。
- 自然语言处理:理解用户输入,提供解答。
- 问题分类:自动分类,快速响应。
- 知识库检索:准确解答问题。
- 智能推荐:根据历史提供产品推荐。
- 多轮对话管理:处理复杂对话,保持连贯性。
- 异常处理:转接人工客服或提供替代方案。
- 用户反馈收集:用于后续优化。
技术需求:
- 大语言模型:使用ChatGLM。
- 知识库:使用LangChain和ChromaDB。
- 系统集成:与现有系统无缝集成。
7.2 构建智能客服系统
第八章 总结
在这五天的学习中,我们一同探索了人工智能世界的奥妙。我们了解了ChatGLM3,这个能够理解和生成自然语言的聊天机器人,以及LangChain,一个连接不同知识和算法的强大工具。我们还学习了如何在Azure平台上使用OpenAl服务,这让我们对云计算有了更深入的认识。
我们深入到了语言模型的核心,学习了如何将词语转化为数字的词嵌入,如何让机器理解语言的位置,以及Transformer模型是如何改变自然语言处理的的游戏规则。我们也了解了作为提示词工程师的挑战和乐趣。
在动手实践环节,我们亲自部署了ChatGLM3-6B,感受到了大型语言模型的强大功能。我们还学习了如何使用ChromaDB这个向量数据库,它能够高效地存储和检索信息,让我们的模型能够更快地响应。
LangChain的原理和实践也让我们眼界大开,我们通过各种例子学习了如何用它来提升模型的性能。我们还了解了微调的概念,学习了如何通过全量微调和PEFT微调来优化我们的模型。
最后,我们将所学应用到实际中,构建了一个智能客服系统,这让我们对大语言模型的实际应用有了更深的理解。这五天学习不仅提升了我们的技术能力,也激发了我们对于人工智能的无限热情。