Pandas基础
![]()
1、什么是Pandas?
Pandas 是一个强大的开源 Python 库,构建在 NumPy 和 Matplotlib 的基础之上,被广泛认为是数据分析的“三剑客”之一。这三个工具分别是 NumPy、Matplotlib 和 Pandas。Pandas 已成为 Python 数据分析的关键工具之一,旨在提供强大且灵活的数据分析功能,可用于支持多种编程语言。
1.1、Pandas概述:
Pandas是一个强大的开源Python库,组合了面板数据(Panel Data)和数据分析(data analysis)的概念,广泛用于数据分析领域。最初应用于金融量化交易,现在在多个行业中得到广泛应用。
1.2、发展历史:

Pandas最初由Wes McKinney于2008年开发,并于2009年开源。目前,由PyData团队进行日常维护。
1.3、Pandas的作用:
在Pandas出现之前,Python主要用于数据采集和数据预处理,但其支持数据分析的能力有限。Pandas的出现显著提升了Python在数据分析领域的能力,它实现了数据分析的五个关键环节:加载数据、整理数据、操作数据、构建数据模型和分析数据。
1.4、Pandas的主要特点:
- 提供了带有默认标签的DataFrame对象,适用于数据分析。
- 能够从不同格式的文件加载数据,并转换为可处理的对象。
- 支持按行和列标签进行分组、聚合和转换操作。
- 方便的数据归一化和处理缺失值。
- 简单地对数据列进行增加、修改或删除。
- 处理不同数据集格式,如矩阵数据、异构数据表和时间序列等。
- 提供多种处理数据集的方法,如构建子集、切片、过滤和重新排序。
1.5、Pandas的主要优势:
Pandas相对于其他语言的数据分析包具有以下优势:
- 提供了适用于数据分析的数据结构,如DataFrame和Series。
- 具有简洁的API,使用户能够专注于核心编程任务。
- 集成了其他库,如Scipy、scikit-learn和Matplotlib。
- 提供完善的资料支持和强大的社区环境。
1.6、Pandas内置数据结构:
Pandas内置了两种主要数据结构:
- Series:带标签的一维数组,标签可以是字符类型。
- DataFrame:表格型数据结构,具有行标签和列标签。
下面表对数据结构做简单地的说明:
| 数据结构 | 维度说明 |
|---|---|
| Series | 该结构能够存储各种数据类型,包括字符、整数、浮点数、Python对象等。Series使用name和index属性来描述数据值。Series是一维数据结构,用于表示序列数据。 |
| DataFrame | 该结构能够存储各种数据类型,包括字符、整数、浮点数、Python对象等。DataFrame使用columns和index属性来描述数据值。DataFrame是二维数据结构,用于表示表格型数据。 |
2、Pandas安装
2.1、Python环境准备
首先你需要准备一个Python环境。
Python下载地址:https://www.python.org/downloads/
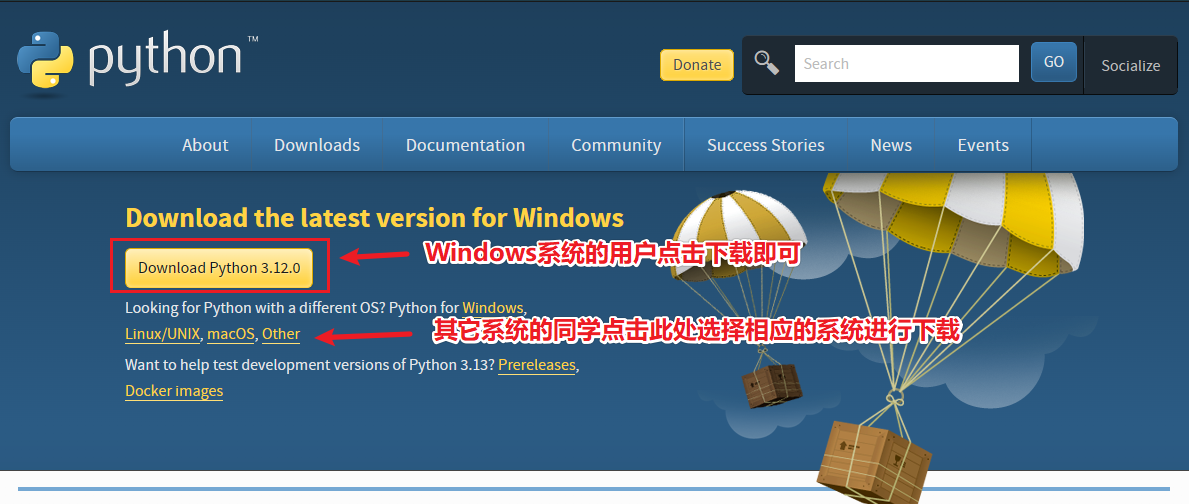
下载好后双击打开Python安装包。

将Add Python.exe to Path打勾,点击Install Now即可。
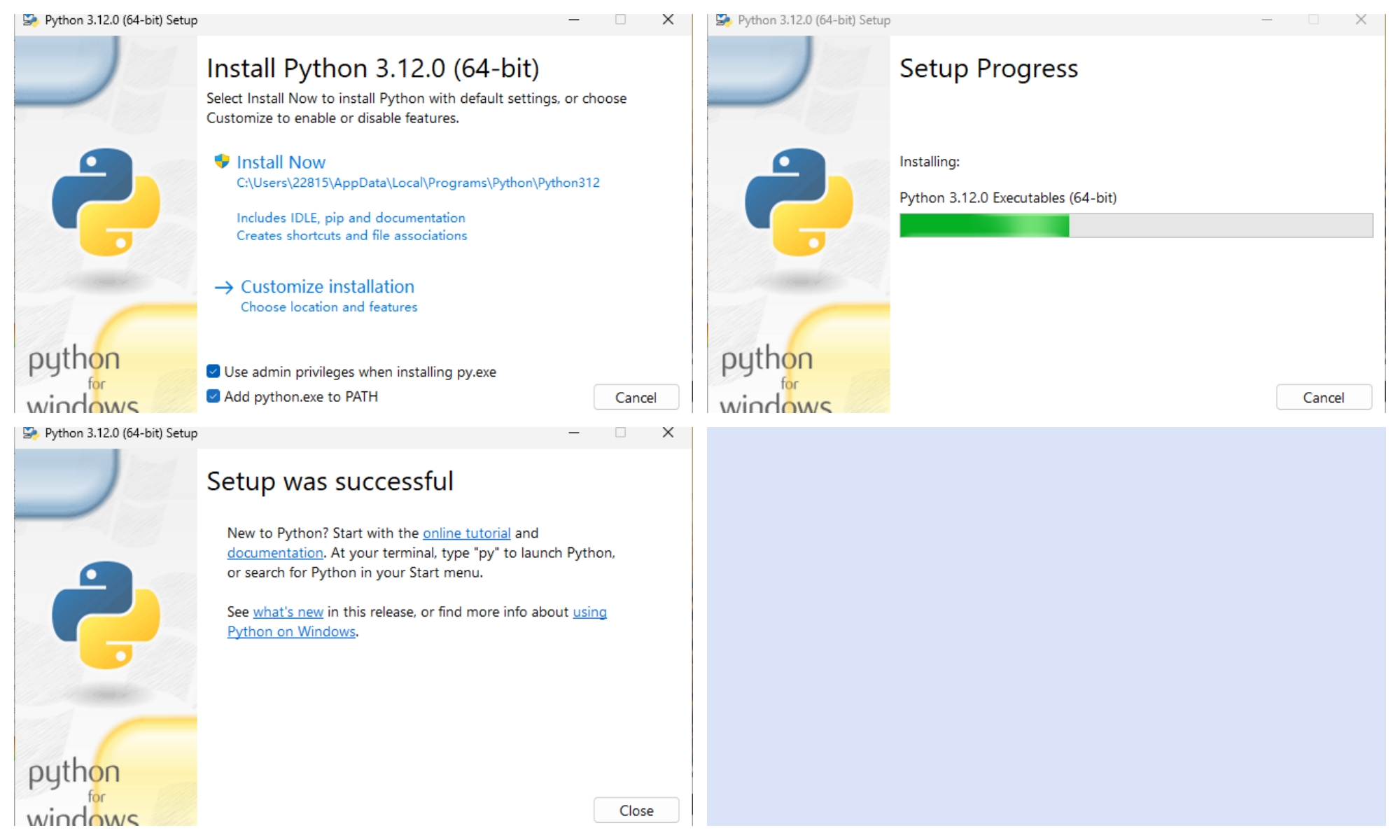
2.2、Pandas安装

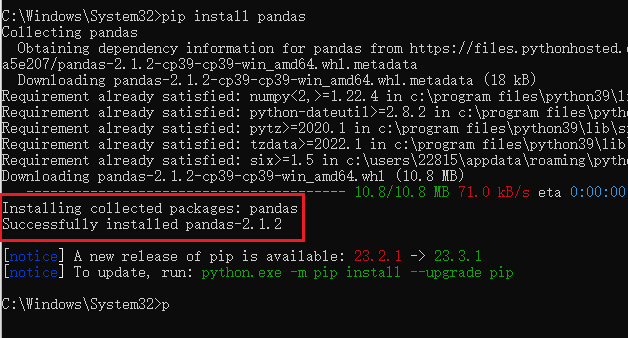
在键盘中按组合键:Win键+R,输入cmd呼出终端,输入如下命令。
1 | pip install pandas |
看到红框中的字样则代表已经成功安装Pandas了。
3、Series入门
Series结构简介: Series,也称为Series序列,是Pandas中常用的数据结构之一。它类似于一维数组,由一组数据值(value)和一组标签(index)组成,其中标签与数据值一一对应。
Series的特点:
- Series可以保存各种数据类型,包括整数、字符串、浮点数、Python对象等。
- 默认情况下,Series的标签是整数,从0开始依次递增。
- Series的结构图如下所示:

3.1、创建Series对象
当使用Pandas库时,可以通过调用Series()函数来创建Series对象。通过这个对象,你可以使用各种方法和属性来处理数据,以达到数据处理的目的。
1 | import pandas as pd |
参数说明:
| 参数名称 | 描述 |
|---|---|
| data | 输入的数据,可以是列表、常量、ndarray 数组等。 |
| index | 索引值必须是惟一的,如果没有传递索引,则默认为 np.arrange(n)。 |
| dtype | dtype表示数据类型,如果没有提供,则会自动判断得出。 |
| copy | 表示对 data 进行拷贝,默认为 False。 |
我们可以使用不同方法来创建Pandas Series对象,包括使用数组、字典、标量值或Python对象。以下是展示创建Series对象的不同方法:
1) 创建一个空Series对象
使用以下方法可以创建一个空的 Series 对象,如下所示:
1 | import pandas as pd |
输出结果:
1 | Series([], dtype: object) |
2) ndarray创建Series对象
ndarray是NumPy中的数组类型。当数据(data)是ndarray时,传递的索引长度必须与数组相同。如果未显式传递索引参数,那么默认情况下,索引将使用range函数生成。下面是使用默认索引创建Series序列对象的示例,输出结果如下:
1 | import pandas as pd |
输出结果:
1 | 100 a |
3) dict创建Series对象
你可以将字典作为输入数据。
如果没有传入索引,将会使用字典的键来构造索引。
反之,如果传递了索引,需要确保索引标签与字典中的值一一对应。
以下是两组示例,分别演示了上述两种情况:
示例 1:
1 | import pandas as pd |
输出结果:
1 | a 0.0 |
示例 2:
1 | import pandas as pd |
输出结果:
1 | b 1.0 |
当传递的索引值无法找到与其对应的值时,就会使用 NaN(非数字)来进行填充。
4) 标量创建Series对象
如果 data 是标量值,则必须提供索引,示例如下:
1 | import pandas as pd |
输出结果:
1 | 0 5 |
标量值按照 index 的数量进行重复,并与其一一对应。
3.2、访问Series数据
上述讲解了创建 Series 对象的多种方式,那么我们应该如何访问 Series 序列中元素呢?
分为两种方式:
位置索引访问
标签索引访问
这种访问方式与 ndarray 和 list 相同,使用元素自身的下标进行访问。我们知道数组的索引计数从 0 开始,这表示第一个元素存储在第 0 个索引位置上,以此类推,就可以获得 Series 序列中的每个元素。
1) 位置索引访问
例 1:通过索引下标访问元素
1 | import pandas as pd |
输出结果:
1 | 1 |
例 2:通过切片的方式访问 Series 序列中的数据
1 | import pandas as pd |
输出结果:
1 | a 1 |
如果想要获取最后三个元素,也可以使用下面的方式:
1 | import pandas as pd |
输出结果:
1 | c 3 |
2) 索引标签访问
Series类似于固定大小的字典,其中将索引标签视为键(key),将序列中的元素值视为对应的值(value)。通过索引标签可以访问或修改元素的值。
例 1:通过标签下标访问元素
1 | import pandas as pd |
输出结果:
1 | 6 |
例 2:使用索引标签访问多个元素值
1 | import pandas as pd |
输出结果:
1 | a 6 |
例 3:使用不存在的标签下标访问元素
1 | import pandas as pd |
输出结果:
1 | . |
3.3、Series常用属性
下面我们介绍 Series 的常用属性和方法。在下表列出了 Series 对象的常用属性。
| 名称 | 属性 |
|---|---|
| axes | 返回所有行索引标签的列表。 |
| dtype | 返回对象的数据类型。 |
| empty | 返回一个空的Series对象。 |
| ndim | 返回输入数据的维数。 |
| size | 返回输入数据的元素数量。 |
| values | 以ndarray的形式返回Series对象的值。 |
| index | 返回一个RangeIndex对象,用来描述索引的取值范围。 |
现在创建一个 Series 对象,并演示如何使用上述表格中的属性。
1) axes
返回所有行索引标签的列表
1 | import pandas as pd |
输出结果:
1 | The axes are: |
2) dtype
返回对象的数据类型
1 | import pandas as pd |
输出结果:
1 | The dtype is: |
3) empty
返回一个空的Series对象
1 | import pandas as pd |
输出结果:
1 | 是否为空对象? |
4) ndim
返回输入数据的维数
1 | import pandas as pd |
输出结果:
1 | 0 1.819675 |
5) size
返回 Series 对象的大小(长度)
1 | import pandas as pd |
输出结果:
1 | 0 -1.124088 |
6) values
以数组的形式返回 Series 对象中的数据。
1 | import pandas as pd |
输出结果:
1 | 0 0.718159 |
7) index
返回一个RangeIndex对象,用来描述索引的取值范围
1 | import pandas as pd |
输出结果:
1 | Index(['a', 'b', 'c', 'd'], dtype='object') |
3.4、 Series常用方法
1) head、tail函数查看数据
要查看Series的一部分数据,可以使用head()或tail()方法。head()方法返回前n行数据,如果不指定n,默认显示前5行数据。
head函数
1 | import pandas as pd |
输出结果:
1 | 原始数据: |
tail函数
tail() 返回的是后 n 行数据,默认为后 5 行
1 | import pandas as pd |
输出结果:
1 | 原始数据: |
2) isnull、nonull函数检测缺失值
isnull()和notnull()方法用于检测Series中的缺失值。缺失值是指数据中不存在、丢失或缺少的值。
isnull(): 如果值不存在或缺失,则返回True。notnull(): 如果值不存在或缺失,则返回False。
在实际数据分析中,数据的收集通常经历复杂的过程,可能由于不可抗力或人为因素导致数据丢失。为了处理这些缺失值,可以使用这两种方法,例如进行均值插值或数据补齐等处理。以下是示例代码和输出结果:
1 | import pandas as pd |
输出结果:
1 | 0 False |
4、DataFrame入门
DataFrame是Pandas中的关键数据结构之一,也是在数据分析中最常用的结构之一。可以说,熟练掌握DataFrame的用法将为学习数据分析提供坚实的基础能力。
4.1、认识DataFrame结构
DataFrame是一种表格型的数据结构,它同时具有行标签(index)和列标签(columns),因此也被称为异构数据表。异构表示表格中每列的数据类型可以不同,可以包括字符串、整数、浮点数等。
如下表:第一列的属于索引列,而name,age,gender,rating属于列标签。
| index | name | age | gender | rating |
|---|---|---|---|---|
| 0 | Alice | 28 | Female | 4.5 |
| 1 | Bob | 35 | Male | 4.0 |
| 2 | Charlie | 22 | Male | 3.5 |
| 3 | Diana | 30 | Female | 4.2 |
| 4 | Eve | 25 | Female | 4.8 |
DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。在数据分析任务中 DataFrame 的应用非常广泛,因为它描述数据的更为清晰、直观。
DataFrame也自带行标签索引,默认使用“隐式索引”,从0开始递增。当然,你也可以使用“显式索引”的方式来设置行标签。
以下是对DataFrame数据结构的特点的简要总结:
- DataFrame每列的标签值可以使用不同的数据类型。
- DataFrame是一种表格型数据结构,包括行和列。
- DataFrame中的每个数据值都可以被修改。
- DataFrame的行数和列数可以动态增加或删除。
- DataFrame有两个方向的标签轴,分别是行标签和列标签。
- DataFrame可以执行行和列级别的算术运算。
上表每一个列标签所对应数据类型如下所示:
| 字段 | 含义 | 类型 |
|---|---|---|
| name | 姓名 | String |
| age | 年龄 | integer |
| gender | 性别 | String |
| rating | 评级 | Float |
4.2、创建DataFrame对象
创建 DataFrame 对象的语法格式如下:
1 | import pandas as pd |
参数说明:
| 参数名称 | 说明 |
|---|---|
| data | 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。 |
| index | 行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。 |
| columns | 列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。 |
| dtype | dtype表示每一列的数据类型。 |
| copy | 默认为 False,表示复制数据 data。 |
Pandas 提供了多种创建 DataFrame 对象的方式,主要包含以下五种,分别进行介绍。
使用下列方式创建一个空的 DataFrame,这是 DataFrame 最基本的创建方法。
1) 创建空的DataFrame对象
使用下列方式创建一个空的 DataFrame,这是 DataFrame 最基本的创建方法。
1 | import pandas as pd |
输出结果:
1 | Empty DataFrame |
2) 列表创建DataFame对象
可以使用单一列表或嵌套列表来创建一个 DataFrame。
例 1:单一列表创建 DataFrame:
1 | import pandas as pd |
输出结果:
1 | 0 |
例 2:使用嵌套列表创建 DataFrame 对象
1 | import pandas as pd |
输出结果:
1 | Name Age |
例 3:指定数值元素的数据类型为 float
1 | import pandas as pd |
输出结果:
1 | Name Age |
3) 字典嵌套列表创建
在数据字典中,每个键对应的值都必须具有相同的元素长度,也就是说它们的列表长度必须相同。
例 1:如果没有传递index索引参数,那么默认情况下,索引将被设置为 range(n),其中 n 表示数组的长度。
1 | import pandas as pd |
例 2:自定义索引,index 参数是一个数组,每个元素对应一行。
1 | import pandas as pd |
输出结果如下:
1 | Name Age |
4) 列表嵌套字典创建DataFrame对象
例 1:列表嵌套字典可以作为输入数据传递给 DataFrame 构造函数。默认情况下,字典的键被用作列名。
注意:如果其中某个元素值缺失,也就是字典的 key 无法找到对应的 value,将使用 NaN 代替。
1 | import pandas as pd |
输出结果:
1 | a b c |
例2:添加行标签索引
1 | import pandas as pd |
输出结果:
1 | a b c |
例 3: 使用字典嵌套列表以及行、列索引表创建一个 DataFrame 对象。
注意:因为 b1 在字典键中不存在,所以对应值为 NaN。
1 | import pandas as pd |
输出结果:
1 | a b |
5) Series创建DataFrame对象
注意:对于 one 列而言,此处虽然显示了行索引 ‘d’,但由于没有与其对应的值,所以它的值为 NaN。
1 | import pandas as pd |
输出结果:
1 | one two |
4.3、列索引操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作。下面依次对这些操作进行介绍。
1) 列索引选取数据列
使用列索引,轻松实现数据选取
1 | import pandas as pd |
输出结果:
1 | a 1.0 |
2) 列索引添加数据列
例 1:使用 columns 列索引表标签可以实现添加新的数据
1 | import pandas as pd |
输出结果:
1 | one two three |
上述示例,我们初次使用了 DataFrame 的算术运算,这和 NumPy 非常相似。
例 2:除了使用df[] = value的方式外,还可以使用 insert() 方法插入新的列。
1 | import pandas as pd |
输出结果:
1 | name age |
3) 列索引删除数据列
通过 del 和 pop() 都能够删除 DataFrame 中的数据列
1 | import pandas as pd |
输出结果:
1 | Our dataframe is: |
4.4、行索引操作
理解了上述的列索引操作后,行索引操作就变的简单。下面看一下,如何使用行索引来选取 DataFrame 中的数据。
1) 标签索引选取
可以将行标签传递给 loc 函数,来选取数据。
注意:loc 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引。
1 | import pandas as pd |
输出结果:
1 | one 2.0 |
2) 整数索引选取
通过将数据行所在的索引位置传递给 iloc 函数,也可以实现数据行选取。
注意:iloc 允许接受两个参数分别是行和列,参数之间使用“逗号”隔开,但该函数只能接收整数索引。
1 | import pandas as pd |
输出结果:
1 | one 3.0 |
3) 切片操作多行选取
你也可以使用切片的方式同时选取多行。
1 | import pandas as pd |
输出结果:
1 | one two |
4) 添加数据行
使用 append() 函数,该函数会在行末追加数据行。
1 | import pandas as pd |
输出结果:
1 | a b |
5) 删除数据行
可以使用drop函数传入行索引标签,从 DataFrame 中删除某一行数据。
如果索引标签存在重复,那么它们将被一起删除
1 | import pandas as pd |
输出结果:
1 | a b |
4.5、常用属性和方法汇总
DataFrame 的属性和方法,与 Series 相差无几。
| 名称 | 属性&方法描述 |
|---|---|
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型。 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True。 |
| ndim | 轴的数量,也指数组的维数。 |
| shape | 返回一个元组,表示了 DataFrame 维度。 |
| size | DataFrame中的元素数量。 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |
| shift() | 将行或列移动指定的步幅长度 |
下面对 DataFrame 常用属性进行演示,首先我们创建一个 DataFrame 对象。
1 | import pandas as pd |
输出结果:
1 | Name years Rating |
1) T(Transpose)转置
返回 DataFrame 的转置,也就是把行和列进行交换
1 | import pandas as pd |
输出结果:
1 | 0 1 2 3 4 |
2) axes
返回一个行标签、列标签组成的列表
1 | import pandas as pd |
输出结果:
1 | [RangeIndex(start=0, stop=5, step=1), Index(['Name', 'years', 'Rating'], dtype='object')] |
3) dtypes
返回每一列的数据类型
1 | import pandas as pd |
输出结果:
1 | Name object |
4) empty
返回一个布尔值,判断输出的数据对象是否为空,若为 True 表示对象为空。
1 | import pandas as pd |
输出结果:
1 | False |
5) ndim
返回数据对象的维数。DataFrame 是一个二维数据结构
1 | import pandas as pd |
输出结果:
1 | 2 |
6) shape
1 | import pandas as pd |
输出结果:
1 | (5, 3) |
7) size
返回 DataFrame 中的元素数量
1 | import pandas as pd |
输出结果:
1 | 15 |
8) values
以 ndarray 数组的形式返回 DataFrame 中的数据。
1 | import pandas as pd |
输出结果:
1 | [['百度' 1 4.95] |
9) head、tail函数查看数据
如果想要查看 DataFrame 的一部分数据,可以使用 head() 或者 tail() 方法。其中 head() 返回前 n 行数据,默认显示前 5 行数据。
例 1:head() 函数返回头部数据
1 | import pandas as pd |
输出结果:
1 | Name years Rating |
例 2:tail() 函数返回尾部数据
1 | import pandas as pd |
输出结果:
1 | Name years Rating |
10) shift函数移动行或列
如果您想要移动 DataFrame 中的某一行/列,可以使用 shift() 函数实现。它提供了一个periods参数,该参数表示在特定的轴上移动指定的步幅。
shif() 函数的语法格式如下:
1 | DataFrame.shift(periods=1, freq=None, axis=0) |
参数说明如下:
| 参数名称 | 说明 |
|---|---|
| peroids | 类型为int,表示移动的幅度,可以是正数,也可以是负数,默认值为1。 |
| freq | 日期偏移量,默认值为None,适用于时间序。取值为符合时间规则的字符串。 |
| axis | 如果是 0 或者 “index” 表示上下移动,如果是 1 或者 “columns” 则会左右移动。 |
| fill_value | 该参数用来填充缺失值。 |
该函数的返回值是移动后的 DataFrame 副本。
10.1) shift的peroids参数
1 | import pandas as pd |
输出结果:
1 | a_data b_data c_data |
10.2) shift的fill_value参数
下面使用 fill_value 参数填充 DataFrame 中的缺失值。
1 | import pandas as pd |
输出结果:
1 | a_data b_data c_data |
5、Pandas描述性统计
描述统计学(descriptive statistics)是统计学领域的分支,专注于获取反映客观现象的数据并通过图表展示和汇总统计量来全面描述和分析数据特征。
Pandas库充分应用了描述统计学的理论,没有这一理论基础,Pandas库的存在可能无从谈起。以下总结了Pandas库中常用的统计学函数:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
从描述统计学角度出发,我们可以对 DataFrame 结构执行聚合计算等其他操作,比如 sum() 求和、mean()求均值等方法。
- 对行操作,默认使用 axis=0 或者使用 “index”;
- 对列操作,默认使用 axis=1 或者使用 “columns”。
创建一个 DataFrame 结构。
1 | import pandas as pd |
输出结果:
1 | Name Age Rating |
1) sum()求和
在默认情况下,返回 axis=0 的所有值的和。
1 | import pandas as pd |
输出结果:
1 | Name AliceBobCharlieDavidEveFrank |
通过例子学习Pandas

第一章 Pandas简介
1.1 什么是Pandas?
Pandas是一个开源的Python库,用于数据分析和数据处理。它为Python提供了快速、灵活且表达能力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。Pandas特别适用于处理诸如表格数据、有序和无序的时间序列、任意矩阵数据(具有行和列标签)的混杂数据类型以及观察统计数据集。
Pandas主要有两种数据结构:
- Series:一维标签数组,能够保存任何数据类型(整数、字符串、浮点数、Python对象等)。Series中的轴标签被统称为索引。
- DataFrame:二维标签数据结构,可以看作是一个Series的容器。DataFrame有行索引和列索引,可以被看作是一个有序的字典,存储了列数据。
很方便和其它类库一起使用:
- numpy:用于数学计算
- scikit-learn:用于机器学习
1.2 安装Pandas
1、下载使用Python类库集成安装包:anaconda
当今最流行的Python数据分析发行版已经安装了数据分析需要的几乎所有的类库
2、pip install pandas
1.3 开发工具
使用jupyter notebook演示
jupyter:交互性、探索性的开发神器,适合学习语法、数据分析;
pycharm:大而全的集成开发环境,适合复杂项目的开发;使用真实数据集做演示
jupyter、代码,提供github仓库下载
第二章 Pandas数据读取
2.1 可读取的数据类型
Pandas需要先读取表格类型的数据,然后进行分析
| 数据类型 | 说明 | Pandas读取方法 |
|---|---|---|
| csv、tsv、txt | 用逗号分隔、tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系型数据库表 | pd.read_sql |
2.2 例子
2.1.1 Pandas读取纯文本文件。
读取csv文件
另存为csv文件:ratings.csv
1,室里,0991-3190109,awYybdzNerQ82SDBwNAizpR3A8yQ@hnuf.cn
2,巴天石,022-82113117,A2EeeQ5z5kdjhP_sNasfWpjxw7@ldu.edu.cn
3,方人智,0375-6019666,K6mZWB3sx364RsRWcetS7BirkX78hkJ@nciae.edu.cn
4,范百龄,0769-22861919,NBJpQkjZmB5NbczC@hlau.cn
5,严三星,024-23894405,XpFrt2@hnsoftedu.com
6,枯荣长老,021-62488077,a27PnPj8FNtSBGtSbN_FRM@hhit.edu.cn
7,天山童姥,021-68021662,NSxBs2pDtCSQjNQkBy@jnzjxy.com.cn
1 | import pandas as pd |
读取txt文件
另存为csv文件:data.txt
1 5/14/2046 2 26
2 4/8/2041 18 76
3 10/6/2116 45 100
4 7/14/2046 69 4
5 5/13/2124 94 36
6 5/29/2113 14 62
7 4/21/2094 86 22
8 1/8/2098 21 18
1 | import pandas as pd |
2.1.2 Pandas读取xlsx格式excel文件
读取excel文件前需要安装openpyxl
点击下载 abc.xlsx
1 | pip install openpyxl |
1 | import pandas as pd |
2.1.3 Pandas读取mysql数据表
数据表格式:
CREATE TABLE
student(
idint(10) UNSIGNED NOT NULL AUTO_INCREMENT,
namevarchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
birthdayvarchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
scoreint(11) NULL DEFAULT NULL,
PRIMARY KEY (id) USING BTREE
) ENGINE = MyISAM AUTO_INCREMENT = 9 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO
studentVALUES (1, ‘左子穆’, ‘1993-1-11’, 4);
INSERT INTOstudentVALUES (2, ‘侯通海’, ‘1992-5-18’, 47);
INSERT INTOstudentVALUES (3, ‘万大平’, ‘1992-3-29’, 93);
INSERT INTOstudentVALUES (4, ‘瘦丐’, ‘2000-12-6’, 58);
INSERT INTOstudentVALUES (5, ‘阿朱’, ‘1999-11-14’, 75);
INSERT INTOstudentVALUES (6, ‘木华黎’, ‘1998-2-20’, 67);
INSERT INTOstudentVALUES (7, ‘辛国梁’, ‘1992-6-16’, 43);
INSERT INTOstudentVALUES (8, ‘绿竹翁’, ‘1994-8-25’, 88);
1 | import pandas as pd |
第三章 Pandas数据结构
3.1 Series
一维标签数组,能够保存任何数据类型(整数、字符串、浮点数、Python对象等)。Series中的轴标签被统称为索引。
3.2 DataFrame
二维标签数据结构,可以看作是一个Series的容器。DataFrame有行索引和列索引,可以被看作是一个有序的字典,存储了列数据。
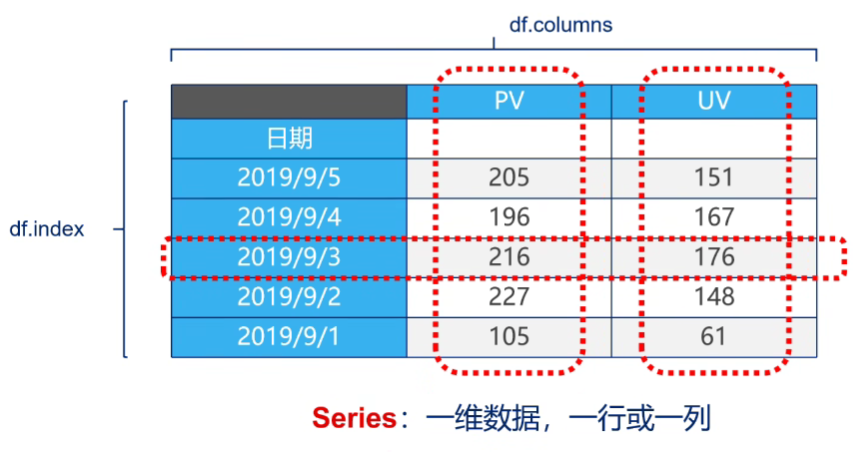
3.3 例子
3.3.1 Series
3.3.1.1 Series例子1:简单例子
1 | import pandas as pd |
3.3.1.2 Series例子2:自定义索引例子
1 | import pandas as pd |
3.3.1.3 Series例子3:使用Python字典创建Series
1 | import pandas as pd |
3.3.1.4 Series例子4:根据标签索引查询数据
类似Python的字典Dict
1 | s2 |
3.3.2 DataFrame
DataFrame是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引index也有列索引columns
- 可以被看做由Series组成的字典
创建dataframe最常用的方法,见02节读取纯文本文件、excel、mysql数据库
3.3.2.1 例子
1 | import pandas as pd |
3.3.3 从DataFrame中查询出Series
如果只查询一行、一列,返回的是pd.Series
如果查询多行、多列,返回的是pd.DataFrame
3.3.3.1 DataFrame例子1:查询列
1 | df['year'] |
3.3.3.2 DataFrame例子2:查询多列,结果是一个pd.DataFrame
1 | df[['year', 'pop']] |
3.3.3.3 DataFrame例子3:查询一行
1 | df.loc[1] |
3.3.3.4 查询多行,结果是一个pd.DataFrame
1 | df.loc[1:3] |
第四章 Pandas数据查询
Pandas查询数据的几种方法
4.1 df.loc方法,根据行、列的标签值查询
将如下数据另存为:beijing_tianqi_2018.csv文件
ymd,bWendu,yWendu,tianqi,fengxiang,fengli,aqi,aqiInfo,aqiLevel
2018-01-01,3℃,-6℃,晴多云,东北风,1-2级,59,良,2多云,东北风,1-2级,49,优,1
2018-01-02,2℃,-5℃,阴
2018-01-03,2℃,-5℃,多云,北风,1-2级,28,优,1
2018-01-04,0℃,-8℃,阴,东北风,1-2级,28,优,1
2018-01-05,3℃,-6℃,多云~晴,西北风,1-2级,50,优,1
数据预处理:
1 | import pandas as pd |
Pandas使用df.loc查询数据的方法
4.1.1 使用单个label值查询数据
1 | # 得到单个值 |
4.1.2 使用值列表批量查询
1 | # 得到Series |
4.1.3 使用数值区间进行范围查询
注意:区间既包含开始,也包含结束
1 | # 行index按区间 |
4.1.4 使用条件表达式查询
bool列表的长度得等于行数或者列数
1 | # 简单条件查询,最低温度低于-10度的列表 |
4.1.5 调用函数查询
1 | # 直接写lambda表达式 |
注意:
- 以上查询方法,既适用于行,也适用于列
- 注意观察降维dataFrame>Series>值
4.2 df.iloc方法,根据行、列的数字位置查询
df.iloc 方法是 pandas DataFrame 的一个功能强大的索引器,用于基于行、列的整数位置进行数据选择。它允许你通过指定明确的行和列的位置索引来选取数据子集。iloc 方法接受两个主要参数:iloc[row_indexer, column_indexer]。
row_indexer表示行的位置索引,可以是单个整数、整数列表或整数切片。column_indexer表示列的位置索引,同样可以是单个整数、整数列表或整数切片。
下面是一些使用df.iloc的例子:使用1
2
3
4
5
6
7
8
9
10# 选择第一行
first_row = df.iloc[0]
# 选择第一列
first_column = df.iloc[:, 0]
# 选择第一行第一列的单个值
first_value = df.iloc[0, 0]
# 选择前五行和前两列
first_five_rows_two_columns = df.iloc[:5, :2]
# 选择特定的几行和几列
rows_and_columns = df.iloc[1:4, 0:3]iloc时,索引是从 0 开始的,并且与 DataFrame 的实际行列位置一一对应。
4.3 df.where方法
df.where 方法用于根据指定的条件来替换 DataFrame 中的值。它允许你将不符合条件的值替换为一个指定的值,而不改变其他值。where 方法通常与 other 参数一起使用,other 参数指定了不符合条件的值应当被替换成的值。
1 | # 将 DataFrame 中所有小于 0 的值替换为 0 |
df.where 方法不会修改原始 DataFrame,它会返回一个新的 DataFrame。
4.4 df.query方法
df.query 方法允许你通过字符串表达式来筛选 DataFrame 中的数据。这个方法非常方便,尤其是当你需要根据复杂的条件筛选数据时。你可以使用标准的 Python 表达式以及列名来编写查询字符串。
1 | # 筛选 'column_name' 列中值大于 10 的行 |
df.query 方法同样不会修改原始 DataFrame,而是返回一个新的 DataFrame,其中只包含满足查询条件的行。
第五章 Pandas新增数据
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析。
5.1 直接赋值
1 | # 替换掉温度的后缀℃ |
5.2 df.apply方法
沿DataFrame的轴应用函数。
传递给该函数的对象是Series对象,其索引是DataFrame的索引(轴=0)或DataFrame的列(轴=1)。
实例:添加一列温度类型:
- 如果最高温度大于33度就是高温
- 低于-10度是低温
- 否则是常温
1 | def get_wendu_type(x): |
5.3 df.assign方法
为DataFrame分配新列。
返回一个新对象,除新列外,还包含所有原始列。
实例:将温度从摄氏度变成华氏度
1 | # 可以同时添加多个新的列 |
5.4 按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大
1 | #先创建空列(这是第一种创建新列的方法) |
第六章 Pandas数据统计函数
6.1 汇总类统计
1 | # 提示所有数字列统计结果 |
6.2 唯一去重和按值计数
一般不用于数值列,而是枚举、分类列。
6.2.1 唯一性去重
1 | df["fengxiang"].unique() |
6.2.2 按值计数
1 | df["fengxiang"].value_counts() |
6.3 相关系数与协方差
应用场景(非常强大):
- 判断两只股票是否同涨同跌,以及相关程度和方向(正相关或负相关)。
- 分析产品销量波动与各种因素之间的相关性,判断是正相关还是负相关,并量化其程度。
知乎解释:
对于两个变量X和Y: - 协方差:衡量两个变量同向或反向变化的程度。协方差为正表示X和Y同向变化,协方差值越大,同向程度越高;协方差为负表示X和Y反向变化,协方差值越小,反向程度越高。
- 相关系数:衡量两个变量变化时的相似度。相关系数为1时,表示两个变量完全正相关;相关系数为-1时,表示两个变量完全负相关。
代码示例:通过上述代码,我们可以得到数据框(DataFrame)中各变量间的协方差矩阵和相关系数矩阵,以及特定变量间(如空气质量和温度)的相关系数。这些统计量有助于我们深入理解变量间的相互关系。1
2
3
4
5
6
7
8
9# 计算协方差矩阵
cov_matrix = df.cov()
# 计算相关系数矩阵
corr_matrix = df.corr()
# 查看空气质量和最高温度的相关系数
aqi_bWendu_corr = df["aqi"].corr(df["bWendu"])
aqi_yWendu_corr = df["aqi"].corr(df["yWendu"])
# 查看空气质量和温差的相关系数
aqi_temp_diff_corr = df["aqi"].corr(df["bWendu"] - df["yWendu"])
协方差用于衡量两个变量的总体误差。计算公式如下:
$$
\text{协方差}(X, Y) = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{n-1}
$$
其中:
- $ X $ 和 $ Y $ 是两个变量。
- $ x_i $ 和 $ y_i $ 分别是两个变量的观测值。
- $ \bar{x} $ 和 $ \bar{y} $ 是两个变量的均值。
- $ n $ 是观测值的数量。
这个公式可以分解为以下几个步骤:
- 对于每个变量,从其每个观测值中减去该变量的均值,得到偏差。
- 将一个变量的偏差与另一个变量的偏差相乘。
- 将所有这些乘积相加。
- 将总和除以 $ n-1 $(这是为了得到样本协方差,如果是总体协方差,则除以 $ n $)。
现在,我将使用Python来演示如何计算两个数据序列的协方差。1
2
3
4
5
6
7
8
9
10import numpy as np
# 示例数据
x = np.array([1, 2, 3, 4, 5])
y = np.array([5, 4, 3, 2, 1])
# 计算均值
mean_x = np.mean(x)
mean_y = np.mean(y)
# 计算协方差
cov_xy = np.sum((x - mean_x) * (y - mean_y)) / (len(x) - 1)
cov_xy
-2.5
计算结果显示,这两个数据序列 $ x $ 和 $ y $ 的协方差为 -2.5。这表明它们之间存在负相关关系,即当一个变量增加时,另一个变量倾向于减少。
第七章 Pandas缺失值处理
7.1 缺失值填充函数
Pandas使用这些函数处理缺失值:
isnull和notnull:检测是否是空值,可用于df和series
dropna:丢弃、删除缺失值
- axis:删除行还是列,{0 or ‘index’,1 or ‘columns”}, default 0
- how:如果等于any则任何值为空都删除,如果等于al则所有值都为空才删除
- inplace:如果为True则修改当前df,否则返回新的df
fillna:填充空值
- value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
- method:等于fill使用前一个不为空的值填充forword fill; 等于bfill使用后一个不为空的值填充backword fill
- axis:按行还是列填充,{0 or ‘index’, 1 or ‘columns’}
- inplace:如果为True则修改当前df,否则返回新的df
7.2 例子:
示例数据:student_data_example.xlsx
1 | # 步骤1:读取excel的时候,忽略前几个空行 |
第八章 Pandas的SettingWithCopyWarning报警
8.1 错误的复现
1 | import pandas as pd |
8.2 原因
发出警告的代码 df[condition]["wen_cha"] = df["bWendu"] - df["yWendu"]
相当于:df.get(condition).set(wen cha),第一步骤的get发出了报警
链式操作其实是两个步骤,先get后set,get得到的dataframe可能是view也可能是copy,pandas发出警告
官网文档:https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
核心要诀:pandas的dataframe的修改写操作,只允许在源dataframe上进行,一步到位
8.3 解决方法
8.3.1 方案1
将get+set的两步操作,改成set的一步操作
1 | df.loc[condition, "wen_cha"] = df["bWendu"] - df["yWendu"] |
8.3.2 方案2
如果需要预筛选数据做后续的处理分析,使用copy复制dataframe
1 | df_month3 = df[condition].copy() |
总之,pandas不允许先筛选子dataframe,再进行修改写入
要么使用.loc实现一个步骤直接修改源dataframe
要么先复制一个子dataframe再一个步骤执行修改
第九章 Pandas数据排序
Series的排序:
1 | Series.sort_values(ascending=True, inplace=False) |
参数说明:
- ascending:默认为True升序排序,为False降序排序。
- inplace:是否修改原始Series
DataFrame的排序:
1 | DataFrame.sort_values(by, ascending=True, inplace=False) |
参数说明:
- by:字符串或者List<字符串>,单列排序或者多列排序
- ascending:bool或者List,升序还是降序,如果是list对应by的多列
- inplace:是否修改原始DataFrame
9.1 Series排序
1 | df["aqi"].sort_values() |
9.2 DataFrame排序
1 | # 按空气质量等级、最高温度排序,默认升序 |
第十章 Pandas字符串处理
前面我们已经使用了字符串的处理函数:
1 | df["bWendu"].str.replace("℃", "").astype("int32") |
Pandas的字符串处理:
- 使用方法:先获取Series的str属性,然后在属性上调用函数
- 只能在字符串列上使用,不能数字列上使用
- Dataframe上没有str属性和处理方法
- Series.str并不是Python原生字符串,而是自己的一套方法,,不过大部分和原生str很相似
Series.str字符串方法列表参考文档:
https://pandas.pydata.org/pandas-docs/stable/reference/series.html#string-handling
10.1 获取Series的str属性,使用各种字符串处理函数
1 | df["bWendu"].str |
10.2 使用str的startswith、contains等得到bool的Series可以做条件查询
1 | condition = df["ymd"].str.startswith("2018-03") |
10.3 需要多次str处理的链式操作
怎样提取201803这样的数字月份?
- 先将日期2018-03-31替换成20180331的形式
- 提取月份字符串201803
1 | df["ymd"].str.replace("-", "") |
10.4 使用正则表达式的处理
1 | # 添加新列 |
问题:怎样将”2018年12月31日”中的年、月、日三个中文字符去除?
1 | # 方法1:链式replace |
Series.str默认就开启了正则表达式模式
1 | # 方法2:正则表达式替换 |
第十一章 Pandas的axis参数
Pandas的axis参数怎么理解?
axis=0或者”index”:
- 如果是单行操作,就指的是某一行
- 如果是聚合操作,指的是跨行cross rows。
axis=1或者”columns”
- 如果是单列操作,就指的是某一列
- 如果是聚合操作,指的是跨列cross columns
按哪个axis,就是这个axis要动起来(类似被or遍用),其它的axis保持不动
1 | import pandas as pd |
11.1 单列drop,就是删除某一列
1 | # 代表的就是删除某列 |
11.2 单行drop,就是删除某一行
1 | # 代表的就是删除某行 |
11.3 按axis=0/index执行mean聚合操作
反直觉:输出的不是每行的结果,而是每列的结果
1 | df.mean(axis=0) |
指定了按哪个axis,就是这个axis要动起来(类似被for遍历),其它的axis保持不动
第十二章 Pandas的索引index
把数据存储于普通的column列也能用于数据查询,那使用index有什么好处?
index的用途总结:
- 更方便的数据查询;
- 使用index可以获得性能提升;
- 自动的数据对齐功能;
- 更多更强大的数据结构支持
12.1 使用index查询数据
1 | # drop==False, 让索引列还保持在column |
12.2 使用index会提升查询性能
- 如果index是唯一的,Pandas会使用哈希表优化,查询性能为O(1);
- 如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
- 如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N);
12.2.1 实验1
1 | # 将数据随机打散 |
12.2.2 实验2
1 | df_sorted = df_shuffle.sort_index() |
12.3 使用index能自动对齐数据
包括series和dataframe
1 | s1 = pd.Series([1, 2, 3], index=list("abc")) |
12.4 使用index更多更强大的数据结构支持
很多强大的索引数据结构
- Categoricallndex,基于分类数据的Index,提升性能
- Multilndex,多维索引,用于groupby多维聚合后结果等
- Datetimelndex,时间类型索引,强大的日期和时间的方法支持
第十三章 Pandas的Merge语法
Pandas的Merge,相当于Sql的Join,将不同的表按key关联到一个表
merge的语法:
1 | pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x','_y'), copy=True, indicator=False, validate=None) |
- left,right:要merge的dataframe或者有name的Series
- how: join类型,”left’,’right’, ‘outer, “inner’
- on:join的key,left和right都需要有这个key
- left on:left的df或者series的key
- right on:right的df或者seires的key
- left_index,right_index:使用index而不是普通的column做join
- suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是(‘_X,’_y’)
文档地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
本次讲解提纲:
- 电影数据集的join实例
- 理解merge时一对一、一对多、多对多的数量对齐关系
- 理解left join、right join、inner join、outer join的区别
- 如果出现非Key的字段重名怎么办
13.1 电影数据集的join实例
电影评分数据集
是推荐系统研究的很好的数据集
位于本代码目录:./datas/movielens-1m
包含三个文件:
- 用户对电影的评分数据 ratings.dat
- 用户本身的信息数据 users.dat
- 电影本身的数据 movies.dat
可以关联三个表,得到一个完整的大表
数据集官方地址:https://grouplens.org/datasets/movielens/
1 | import pandas as pd |
13.2 理解merge时数量的对齐关系
以下关系要正确理解:
one-to-one:一对一关系,关联的key都是唯一的
比如(学号,姓名)merge(学号,年龄)
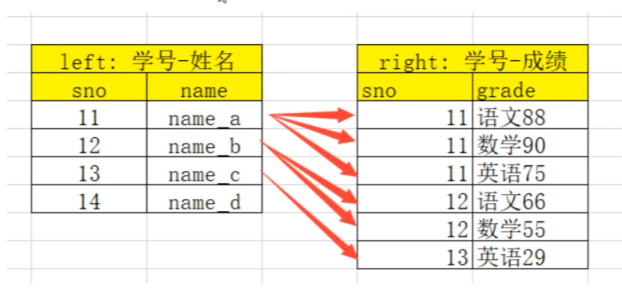
结果条数为:1*1one-to-many:一对多关系,左边唯-key,右边不唯-key。
比如(学号,姓名) merge (学号,[语文成绩、数学成绩、英语成绩])
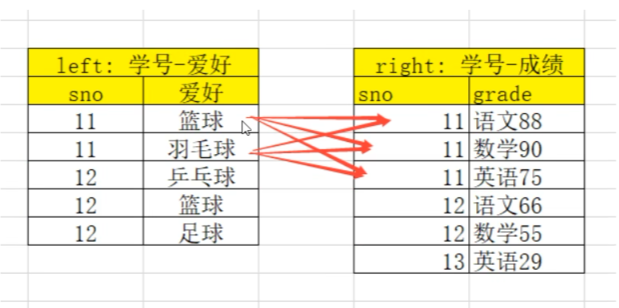
结果条数为:1*Nmany-to-many:多对多关系,左边右边都不是唯一的
比如(学号,[语文成绩、数学成绩、英语成绩]) merge(学号,[篮球、足球、乒乓球])
结果条数为:M*N
13.2.1 one-to-one 一对一关系的merge
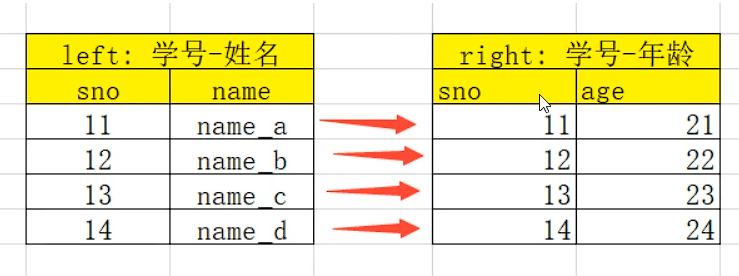
1 | left = pd.DataFrame({ |
13.2.2 one-to-many 一对多关系的merge
注意:数据会被复制
1 | left = pd.DataFrame({ |
13.2.3 many-to-many 多对多关系的merge
注意:结果数量会出现乘法
1 | left = pd.DataFrame({ |
13.3 理解left join、right join、inner join、outer join的区别
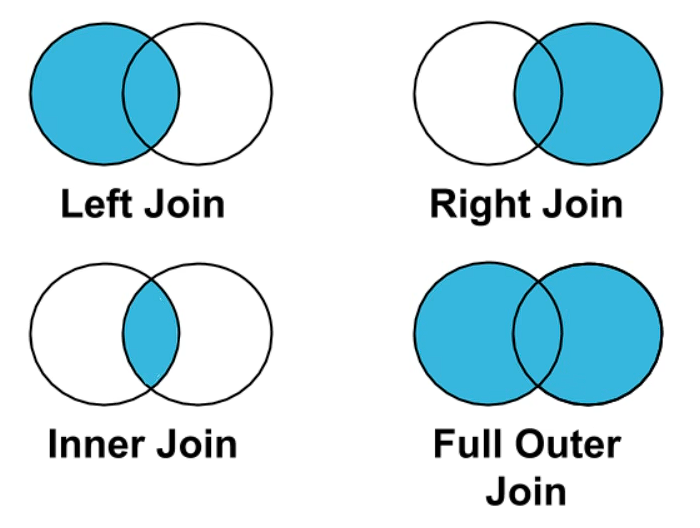
1 | left = pd.DataFrame({ |
13.3.1 inner join 默认
左边和右边的key都有,才会出现在结果里面
1 | pd.merge(left, right, how="inner") |
13.3.2 left join
左边的都会出现在结果里,右边的如果没法匹配则为Null
1 | pd.merge(left, right, how="left") |
13.3.3 right join
右边的都会出现在结果里,左边的如果无法匹配则为Null
1 | pd.merge(left, right, how='right') |
13.3.4 outer join
左边、右边的都会出现在结果里,如果无法匹配则为Null
1 | pd.merge(left, right, how='outer') |
13.4 如果出现非Key的字段重名怎么办?
1 | left = pd.DataFrame({ |
第十四章 Pandas的Concat合并
使用场景:
批量合并相同格式的Excel、给DataFrame添加行、给DataFrame添加列
一句话说明concat语法:
- 使用某种合并方式(inner/outer)
- 沿着某个轴向(axis=0/1)
- 把多个Pandas对象(DataFrame/Series)合并成一个。
concat语法:pandas.concat(objs, axis=0, join=’outer’, ignore_index=False)
- objs:一个列表,内容可以是DataFrame或者Series,可以混合。axis:默认是0代表按行合并,如果等于1代表按列合并
- join:合并的时候索引的对齐方式,默认是outerjoin,也可以是inner join
- ignore_index:是否忽略掉原来的数据索引
append语法:DataFrame.append(other, ignore_index=False)
append只有按行合并,没有按列合并,相当于concat按行的简写形式
- other:单个dataframe、series、dict,或者列表
- ignore_index:是否忽略掉原来的数据索引
参考文档:
pandas.concat的api文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.htm
pandas.concat的教程:https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
pandas.append的api文档:https://pandas.pydata.org/pandas-docs/reference/api/pandas.DataFrame.append.html
14.1 使用pandas.concat合并数据
1 | df1 = pd.DataFrame({ |
14.1.1 默认的concat, 参数为axis=0,join=outer,ignore_index=False
1 | pd.concat([df1, df2]) |
14.1.2 使用ignore_index=True可以忽略原来的索引
1 | pd.concat([df1, df2], ignore_index=True) |
14.1.3 使用join=inner过滤掉不匹配的列
1 | pd.concat([df1, df2], ignore_index=True, join="inner") |
14.1.4 使用axis=1相当于添加新列
1 | df1 |
14.2 使用DataFrame.append按行合并数据
1 | df1 = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB')) |
14.2.1 给1个dataframe添加另一个dataframe
1 | df1.append(df2) |
14.2.2 忽略原来的索引ignore_index=True
1 | df1.append(df2, ignore_index=True) |
14.2.3 可以一行一行的给DataFrame添加数据
1 | # 一个空的df |
A: 低性能版本
1 | for i in range(5): |
B:性能较好的版本
1 | # 第一个入参是一个列表,避免了多次复制 |
第十五章 Pandas批量拆分与合并Excel文件
实例演示:
将一个大Excel等份拆成多个Excel
将多个小Excel合并成一个大Excel并标记来源
1 | work_dir = "./course_datas/c15_excel_split_merge" |
1 | import pandas as pd |
15.1 将一个大Excel等份拆成多个Excel
使用df.iloc方法,将一个大的dataframe,拆分成多个小dataframe
将使用dataframe.to_excel保存每个小Excel
计算拆分后的每个excel的行数
1 | # 这个大excel,会拆分给这几个人 |
- 拆分成多个dataframe
1 | df_subs = [] |
- 将每个datafame存入excel
1
2
3for idx, user_name, df_sub in df_subs:
file_name = f"{splits_dir}/abc_{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name, index=False)
15.2 合并多个小Excel到一个大Excel
- 遍历文件夹,得到要合并的Excel文件列表
1 | import os |
- 分别读取到dataframe,给每个df添加一列用于标记来源
1 | df_list = [] |
- 使用pd.concat进行df批量合并
1 | df_merged = pd.concat(df_list) |
- 将合并后的dataframe输出到excel
1 | df_merged.to_excel(f"{work_dir}/dec.xlsx", index=False) |
第十六章 Pandas实现groupby分组统计
类似SQL:
1 | select city, max(temperature) from city_weather group by city |
groupby:先对数据分组,然后在每个分组上应用聚合函数、转换函数
本次演示:
- 分组使用聚合函数做数据统计
- 遍历groupby的结果理解执行流程
- 实例分组探索天气数据
1 | import pandas as pd |
16.1 分组使用聚合函数做数据统计
16.1.1 单个列groupby,查询所有数据列的统计
1 | df.groupby('A').sum() |
我们看到:
groupby中的’A’变成了数据的索引列
因为要统计sum,但B列不是数字,所以被自动忽略掉
16.1.2 多个列groupby,查询所有数据列的统计
1 | df.groupby(['A', 'B']).mean() |
我们看到:(‘A’, ‘B’)成对变成了二级索引
1 | df.groupby(['A', 'B'], as_index=False).mean() |
16.1.3 同时查看多种数据统计
1 | df.groupby('A').agg([np.sum, np.mean, np.std]) |
16.1.4 查看单列的结果数据统计
1 | # 方法1:预过滤,性能更好 |
16.1.5 不同列使用不同的聚合函数
1 | df.groupby('A').agg({'C': np.sum, 'D': np.mean}) |
16.2 遍历groupby的结果理解执行流程
for循环可以直接遍历每个group
16.2.1 遍历单个列聚合的分组
1 | g = df.groupby('A') |
16.2.2 遍历多个列聚合的分组
1 | g = df.groupby(['A', 'B']) |
可以直接查询group后的某个列,生成Series或者子DataFrame
1 | g['C'] |
其实所有的聚合统计,都是在datafame和series上进行的;
16.3 实例分组探索天气数据
1 | fpath = './datas/beijing_tianqi/beijing_tianqi_2018.csv' |
1 | # 新增一列为月份 |
16.3.1、查看每个月的最高温度
1 | data = df.groupby('month')['bWendu'].max() |
1 | type(data) |
1 | data.plot() |
16.3.2 查看每个月的最高温度、最低温度、平均空气质量指数
1 | df.head() |
1 | group_data = df.groupby('month').agg({"bWendu": np.max, "yWendu": np.min, "aqi": np.mean}) |
1 | group_data.plot() |
第十七章 Pandas的分层索引Multilndex
本实验的数据,可以在:http://tushare.org/index.html#id5进行下载
为什么要学习分层索引Multilndex?
- 分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
- 可以更方便的进行数据筛选,如果有序则性能更好;
- groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用。
- 一般不需要自己创建分层索引(Multilndex有构造函数但一般不用)
- 演示数据:百度、阿里巴巴、爱奇艺、京东四家公司的10天股票数据
数据来自:英为财经 https://cn.investing.com/
1 | import pandas as pd |
17.1 Series的分层索引Multilndex
1 | ser = stocks.groupby(['公司', '日期'])['收盘'].mean() |
多维索引中,空白的意思是:使用上面的值
1 | ser.index |
1 | # unstack把二级索引变成列 |
1 | ser |
17.2 Series有多层索引怎样筛选数据?
1 | ser |
1 | ser.loc['BIDU'] |
1 | # 多层索引,可以用元组的形式筛选 |
1 | ser.loc[:, '2019-10-02'] |
17.3 DataFrame的多层索引Multilndex
1 | stocks.head() |
1 | stocks.set_index(['公司', '日期'], inplace=True) |
1 | stocks.index |
1 | stocks.sort_index(inplace=True) |
17.4 DataFrame有多层索引怎样筛选数据?
【重要知识】在选择数据时
- 元组(key1, key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD,key2=2019-10-02
- 列表(key1, key2)代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD,key2=BIDU
1 | stocks.loc['BIDU'] |
1 | stocks.loc['BIDU', '2019-10-02', :] |
1 | stocks.loc[('BIDU', '2019-10-02', '开盘')] |
1 | stocks.loc[['BIDU', 'JD'], :] |
1 | stocks.loc[(['BIDU', 'JD'], '2019-10-03'), :] |
1 | stocks.loc[(['BIDU', 'JD'], '2019-10-03'), '收盘'] |
1 | stocks.loc[('BIDU', ['2019-10-02', '2019-10-03']), '收盘'] |
1 | # slice(None)代表筛选这一索引的所有内容 |
1 | stocks.reset_index() |
第十八章 Pandas的数据转换函数map、apply、applymap
数据转换函数对比:map、apply、applymap:
- map: 只用于Series,实现每个值->值的映射;
- apply: 用于Series实现每个值的处理,用于Dataframe实现某个轴的Series的处理;
- applymap: 只能用于DataFrame,用于处理该DataFrame的每个元素;
18.1 map用于Series值的转换
实例:将股票代码英文转换成中文名字
Series.map(dict) or Series.map(function) 均可
1 | import pandas as pd |
1 | stocks['公司'].unique() |
1 | # 公司股票代码到中文的映射,注意这里是小写 |
方法1:Series.map(dict)
1 | stocks["公司中文1"] = stocks["公司"].str.lower().map(dict_company_names) |
方法2:Series.map(function)
function的参数是Series的每个元素的值
1 | stocks['公司中文2'] = stocks['公司'].map(lambda x: dict_company_names[x.lower()]) |
1 | stocks.head() |
18.2 apply用于Series和DataFrame的转换
- Series.apply(function), 函数的参数是每个值
- DataFrame.apply(function), 函数的参数是Series
Series.apply(function)
function的参数是Series的每个值
1 | stocks["公司中文3"] = stocks["公司"].apply(lambda x: dict_company_names[x.lower()]) |
1 | stocks.head() |
DataFrame.apply(function)
function的参数是对应轴的Series
1 | stocks["公司中文4"] = stocks.apply( |
注意这个代码:
apply是在stocks这个DataFrame上调用:
lambda x的x是一个Series,因为指定了axis=1所以Seires的key是列名,可以x[‘公司’]获取
18.3 applymap用于DataFrame所有值的转换
1 | sub_df = stocks[['收盘', '开盘', '高', '低', '交易量']] |
1 | sub_df.head() |
1 | # 将这些数字取整数,应用于所有元素 |
1 | # 直接修改原df的这几列 |
1 | stocks.head() |
第十九章 Pandas对每个分组应用apply函数
知识:Pandas的GroupBy遵从split、apply、combine模式
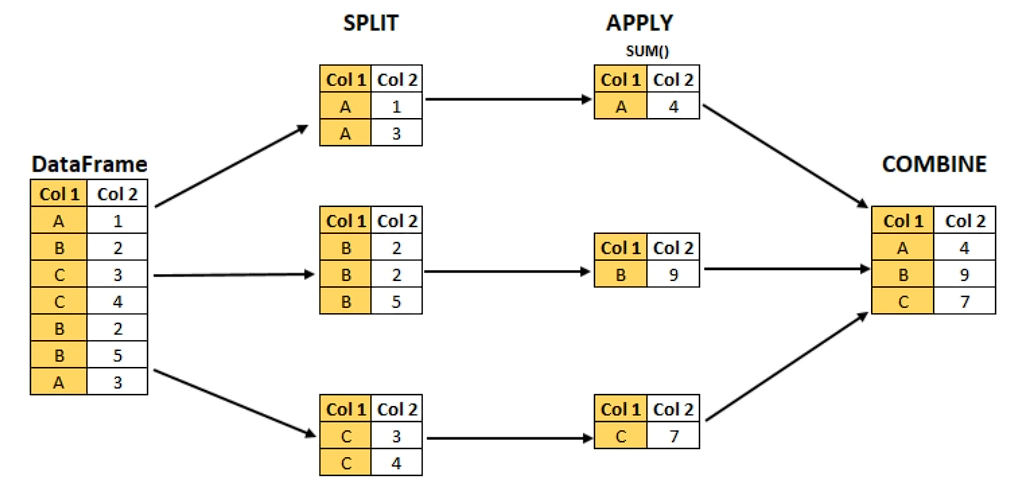
这里的split指的是pandas的groupby,我们自己实现apply函数,apply返回的结果由pandas进行combine得到结果
GroupBy.apply(function)
- function的第一个参数是dataframe
- function的返回结果,可是dataframe、series、单个值,甚至和输入dataframe完全没关系
本次实例演示:
- 怎样对数值列按分组的归一化?
- 怎样取每个分组的TOPN数据?
实例1:怎样对数值列按分组的归一化??
将不同范围的数值列进行归一化,映射到[0,1]区间:
- 更容易做数据横向对比,比如价格字段是几百到几千,增幅字段是0到100
- 机器学习模型学的更快性能更好
归一化的公式:

数据下载:ml-1m.zip
演示:用户对电影评分的归一化
1 | import pandas as pd |
1 | # 实现按照用户ID分组,然后对其中一列归一化 |
1 | ratings[ratings["UserID"] == 1].head() |
可以看到UserID==1这个用户,Rating==3是他的最低分,是个乐观派,我们归一化到0分。
实例2:怎样取每个分组的TOPN数据?
获取2018年每个月温度最高的2天数据
1 | fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv" |
1 | def getWenduTopN(df, topn): |
我们看到,groupby的apply函数返回的dataframe,其实和原来的dataframe其实可以完全不一样
第二十章 Pandas使用stack和pivot实现数据透视
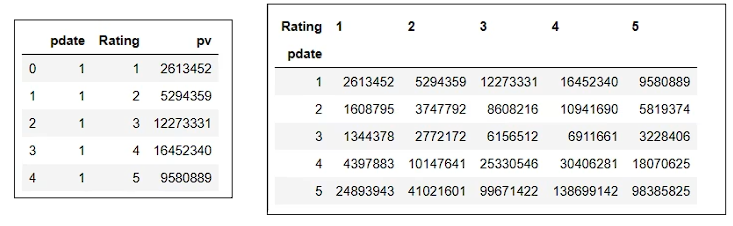
将列式数据变成二维交叉形式,便于分析,叫做重塑或透视
20.1 经过统计得到多维度指标数据
1 | import pandas as pd |
1 | df.head() |
1 | df["pdate"] = pd.to_datetime(df["Timestamp"], unit='s') |
1 | df.head() |
1 | df.dtypes |
1 | # 实现数据统计 |
1 | df_group.head(20) |
对这样格式的数据,我想查看按月份,不同评分的次数趋势,是没法实现的
需要将数据转换成每个评分是一列才可以实现
20.2 使用unstack实现数据二维透视
目的:想要画图对比按照月份的不同评分的数量趋势
1 | df_stack = df_group.unstack() |
1 | df_stack.plot() |
1 | # unstack和stack是互逆操作 |
20.3 使用pivot简化透视
1 | df_group.head(20) |
1 | df_reset = df_group.reset_index() |
1 | df_pivot = df_reset.pivot("pdate", "Rating", "pv") |
1 | df_pivot.head() |
1 | df_pivot.plot() |
pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
20.4 stack、unstack、pivot的语法
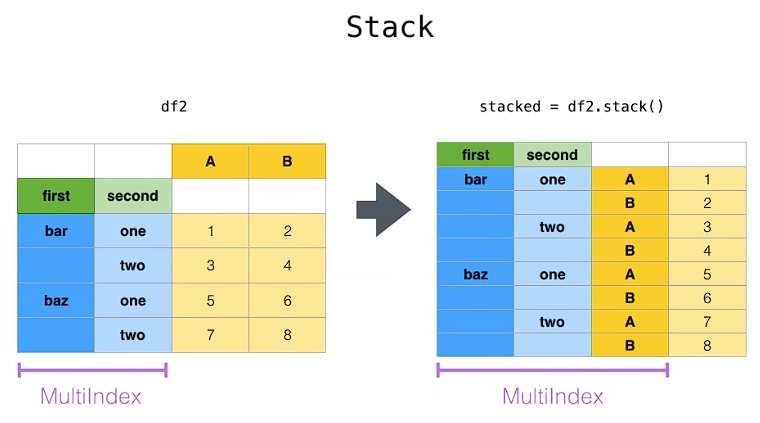
stack:DataFrame.stack(level=-1, dropna=True),将column变成index,类似把横放的书籍变成竖放
level=-1代表多层索引的最内层,可以通过==0、1、2指定多层索引的对应层
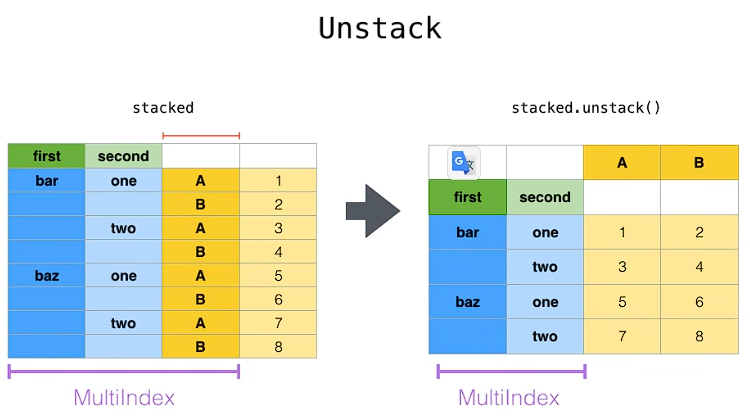
unstack:DataFrame.unstack(level=-1, fill_value=None),将index变成column,类似把竖放的书籍变成横放
pivot: DataFrame.pivot(index=None, columns=None, values=None),指定index、columns、values实现二维透视
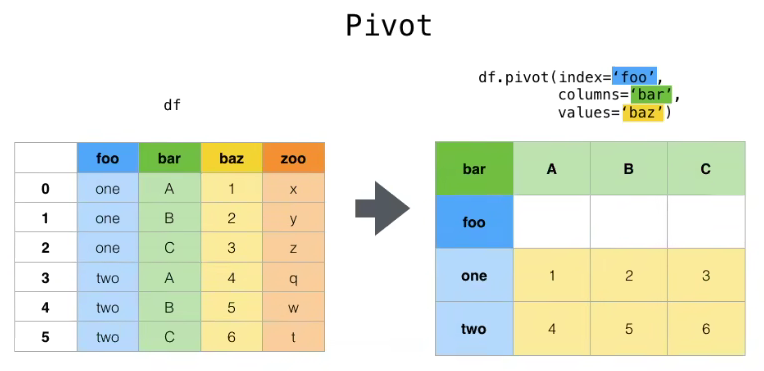
第二十一章 Pandas使用apply函数给表格添加多列
知识回忆:怎样给表格添加一列
1 | def my_func(row): |
新的知识:怎样同时添加多列?
1 | def my_func(row): |
1 | import pandas as pd |
同时添加温差,平均温度
1 | def my_func(row): |
1 | df.head() |
第二十二章 Pandas新增数据列
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析。
读取csv数据到dataframe
1 | fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv" |
1 | df.head() |
21.1 直接赋值
实例:清理温度列,变成数字类型
1 | # 替换掉温度的后缀℃ |
1 | df.head() |
实例:计算温差
1 | # 注意,df["bWendu"]其实是一个Series,后面的减法返回的是Series |
1 | df.head() |
21.2 df.apply方法
沿DataFrame的轴应用函数。
传递给该函数的对象是Series对象,其索引是DataFrame的索引(轴=0)或DataFrame的列(轴=1)
实例:添加一列温度类型:
- 如果最高温度大于33度就是高温
- 低于-10度是低温
- 否则是常温
1 | def get_wendu_type(x): |
1 | # 查看温度类型的计数 |
21.3 df.assign方法
为DataFrame分配新列。
返回一个新对象,除新列外,还包含所有原始列。
实例:将温度从摄氏度变成华氏度
1 | # 可以同时添加多个新的列 |
21.4 按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则任务温差大
1 | # 先创建空列(这是第一种创建新列的方法) |
1 | df["wencha_type"].value_counts() |