实验:机器学习之 K-Means 聚类 第一章 K-Means 介绍 第一节 什么是 K 均值聚类
K-Means 应用案例:
客户细分
了解网站访问者试图完成什么
模式识别
机器学习
数据压缩
第二节 k 均值聚类的目标是什么
第三节 k 均值聚类的工作原理
其具体工作流程如下:
K-Means 伪代码:
1 2 3 4 5 6 7 8 初始化 k 个均值为随机值 重复以下步骤指定的迭代次数: 遍历所有项目: 计算项目与每个均值的欧几里得距离 确定最接近项目的均值 将项目分配给该均值 对于每个簇: 通过计算簇中项目的平均值来更新该簇的均值
第二章 实验部分 第一节 安装环境 1 pip install seaborn pandas numpy matplotlib
第二节 K-Means 聚类实验(纯代码实现) make_blobs函数是sklearn.datasets中的一个函数,主要用于产生聚类数据集,生成一个数据集和相应的标签。以下是make_blobs函数的参数说明:
n_samples:表示数据样本点个数,默认值为 100。n_features:表示每个样本的特征(或属性)数,也表示数据的维度,默认值为 2。centers:表示类别数(标签的种类数),默认值为 3。cluster_std:表示每个类别的方差,浮点数或者浮点数序列,默认值为 1.0。例如,若希望生成 2 类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为浮点数 1.0~3.0。center_box:中心确定之后的数据边界,默认值为(-10.0,10.0)。shuffle:将数据进行洗乱,默认值是True。random_state:官网解释是随机生成器的种子,可以固定生成的数据。给定数之后,每次生成的数据集就是固定的。若不给定值,则由于随机性将导致每次运行程序所获得的结果可能有所不同。在使用数据生成器练习机器学习算法练习或 python 练习时建议给定数值。
2.1 数据初始化 1 2 3 4 5 6 7 8 9 10 11 12 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsX,y = make_blobs(n_samples = 500 , n_features = 2 , centers = 3 , random_state = 23 ) fig = plt.figure(0 ) plt.grid(True ) plt.scatter(X[:,0 ], X[:,1 ]) plt.show()
2.2 初始化随机质心 代码为 K-means 聚类初始化三个聚类。它设置一个随机种子并在指定范围内生成随机簇中心,并为每个簇创建一个空的点列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 k = 3 clusters = {} np.random.seed(23 ) for idx in range (k): center = np.random.uniform(low=-2 , high=2 , size=X.shape[1 ]) points = [] clusters[idx] = { 'center' : center, 'points' : [] } clusters
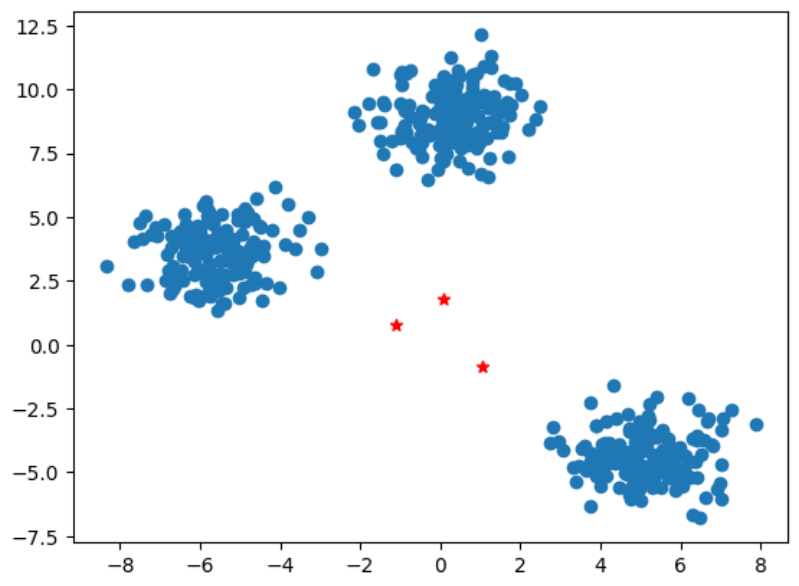
2.3 绘制中心点 该图以网格线显示数据点 $(X[:,0], X[:,1])$ 的散点图。它还标记了 K-means 聚类生成的初始聚类中心(红色星星)。
1 2 3 4 5 6 7 8 9 10 11 12 13 plt.scatter(X[:,0 ], X[:,1 ]) plt.grid(True ) for i in clusters: center = clusters[i]['center' ] plt.scatter(center[0 ],center[1 ],marker = '*' ,c = 'red' ) plt.show()
2.4 定义欧几里得距离
$$
1 2 3 def distance (p1, p2 ): return np.sqrt(np.sum ((p1 - p2) ** 2 ))
2.5 创建分配和更新集群中心的功能 E 步(Expectation 步)是根据当前的聚类中心,计算每个数据点属于每个聚类的概率。
在 K-Means 中,可以通过计算每个数据点到每个聚类中心的距离来确定概率。距离越近,数据点属于该聚类的概率就越高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def assign_clusters (X, clusters ): dots_num = X.shape[0 ] for idx in range (dots_num): dist = [] curr_x = X[idx] for i in range (k): dis = distance(curr_x, clusters[i]['center' ]) dist.append(dis) curr_cluster = np.argmin(dist) clusters[curr_cluster]['points' ].append(curr_x) return clusters
所以,E 步实际上找 一个蓝色的点 与 三个红色星星 对比距离,距离短的,就归属对应的红色星星所有。
M 步(Maximization 步)是根据 E 步计算出的概率,重新计算聚类中心。
在 K-Means 中,更新聚类中心的方法是将属于每个聚类的数据点的平均值作为新的聚类中心。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def update_clusters (X, clusters ): for i in range (k): points = np.array(clusters[i]['points' ]) if points.shape[0 ] > 0 : new_center = points.mean(axis =0 ) clusters[i]['center' ] = new_center clusters[i]['points' ] = [] return clusters
所以,M 步事实上,平均 E 步所收集的点(将收集的点的 x 坐标累加在再平均,y 坐标累加再平均)得到一个新的中心点坐标。
2.6 创建用于预测数据点集群的函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def pred_cluster (X, clusters ): pred = [] dots_num = X.shape[0 ] for i in range (dots_num): dist = [] for j in range (k): d = distance(X[i], clusters[j]['center' ]) dist.append(d) pred.append(np.argmin(dist)) return pred
2.7 赋值、更新中心点位置、推理 1 2 3 4 5 6 7 8 clusters = assign_clusters(X, clusters) clusters = update_clusters(X, clusters) pred = pred_cluster(X, clusters)
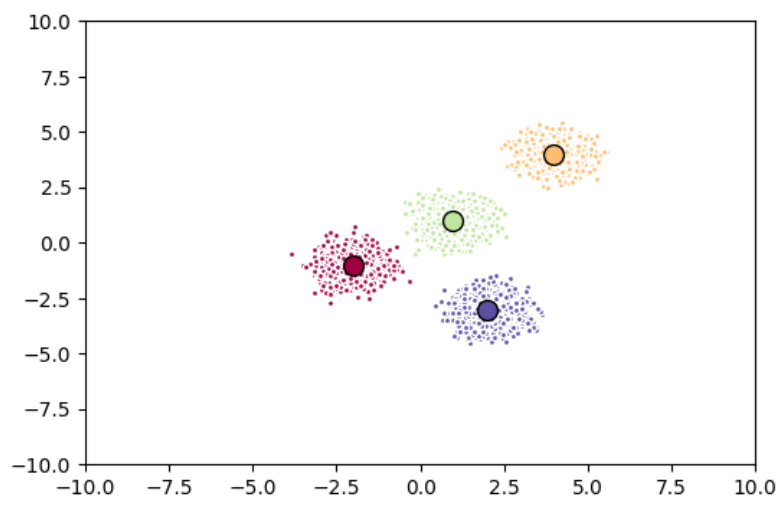
2.8 显示推理结果 1 2 3 4 5 6 7 8 9 10 11 12 plt.scatter(X[:,0 ], X[:,1 ], c = pred) for i in clusters: center = clusters[i]['center' ] plt.scatter(center[0 ], center[1 ], marker = '^' , c = 'red' ) plt.show()
第三节 K-Means 聚类实验(sklearn 实现) 3.1 抑制警告 warn 的函数,它什么也不做(只是直接通过),然后将 warnings 模块中的 warn 方法替换为这个自定义的函数,这样当有警告产生时,就不会实际输出或显示这些警告信息了。
1 2 3 4 5 def warn (*args, **kwargs ): pass import warningswarnings.warn = warn
3.2 数据初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import randomimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn.datasets import make_blobs%matplotlib inline np.random.seed(0 ) centers = [ [4 ,4 ], [-2 , -1 ], [2 , -3 ], [1 , 1 ] ] X, y = make_blobs(n_samples=5000 , centers=centers, cluster_std=0.9 ) plt.scatter(X[:, 0 ], X[:, 1 ], marker='.' )
%matplotlib inline 主要的作用:在使用 Jupyter Notebook 等交互式环境时,它使得 matplotlib 绘制的图形可以直接嵌入在当前的 Notebook 页面内显示,而不是弹出单独的窗口来展示图形。这样方便在 Notebook 中直接查看和交互图形,有助于进行数据分析和可视化的过程。
3.3 设置 K-Means 函数 首先,我们进行 KMeans 设置。现在我们有了随机数据。
KMeans 类有很多可使用的参数,这里我们使用以下三个:
init(初始化质心的方法):值为 "k-means++",表示以一种智能的方式选择初始聚类中心来加速收敛。n_clusters(要形成的簇的数量以及要生成的质心数量):值为 4,因为我们有 4 个中心。n_init 定义了要运行算法的次数,默认情况下,n_init 设置为 10,这意味着算法将在 10 个不同的随机初始质心上运行,并返回最佳结果。
然后,使用这些参数初始化 KMeans,将输出参数命名为 k_means。
1 2 3 4 5 k_means = KMeans(init="k-means++" , n_clusters=4 , n_init=12 ) k_means.fit(X)
3.4 显示图像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 fig = plt.figure(figsize=(6 , 4 )) colors = plt.cm.Spectral(np.linspace(0 , 1 , n_clusters)) ax = fig.add_subplot(1 , 1 , 1 ) plt.xlim(-10 , 10 ) plt.ylim(-10 , 10 ) for k, col in zip (range (n_clusters), colors): my_members = (k_means3.labels_ == k) ax.plot(X[my_members, 0 ], X[my_members, 1 ], 'w' , markerfacecolor=col, marker='.' ) cluster_center = k_means3.cluster_centers_[k] ax.plot(cluster_center[0 ], cluster_center[1 ], 'o' , markerfacecolor=col, markeredgecolor='k' , markersize=10 ) plt.show()
3.5 完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn.datasets import make_blobs%matplotlib inline np.random.seed(0 ) centers = [ [4 ,4 ], [-2 , -1 ], [2 , -3 ], [1 , 1 ] ] X, y = make_blobs(n_samples=5000 , centers=centers, cluster_std=0.5 ) n_clusters = 4 k_means3 = KMeans(init="k-means++" , n_clusters=n_clusters, n_init=12 ) k_means3.fit(X) fig = plt.figure(figsize=(6 , 4 )) colors = plt.cm.Spectral(np.linspace(0 , 1 , n_clusters)) ax = fig.add_subplot(1 , 1 , 1 ) plt.xlim(-10 , 10 ) plt.ylim(-10 , 10 ) for k, col in zip (range (n_clusters), colors): my_members = (k_means3.labels_ == k) ax.plot(X[my_members, 0 ], X[my_members, 1 ], 'w' , markerfacecolor=col, marker='.' ) cluster_center = k_means3.cluster_centers_[k] ax.plot(cluster_center[0 ], cluster_center[1 ], 'o' , markerfacecolor=col, markeredgecolor='k' , markersize=10 ) plt.show()
第四节 K-Means 聚类鸢尾花分类实验(sklearn 实现)
4.1 加载鸢尾花数据 1 2 3 4 5 6 7 8 9 import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.cm as cmfrom sklearn.datasets import load_irisfrom sklearn.cluster import KMeansX, y = load_iris(return_X_y=True )
4.2 找到最佳簇数 1 2 3 4 5 6 sse = [] for k in range (1 ,11 ): km = KMeans(n_clusters=k, random_state=2 ) km.fit(X) sse.append(km.inertia_)
4.3 显示簇数与误差的关系 “Sum Squared Error”的意思是“误差平方和”或“平方误差总和”。
$$
它常被用于评估模型预测值与实际值之间的偏差程度。
1 2 3 4 5 6 7 8 sns.set_style("whitegrid" ) g=sns.lineplot(x=range (1 , 11 ), y=sse) g.set (xlabel ="Number of cluster (k)" , ylabel = "Sum Squared Error" , title ='Elbow Method' ) plt.show()
从上图中,我们可以观察到,在 k=2 和 k=3 时,肘状的情况。我们考虑 K=3。
4.4 构建 Kmeans 聚类模型 1 2 kmeans = KMeans(n_clusters=3 , random_state=2 ) kmeans.fit(X)
4.5 找到簇中心 4.6 推理 1 2 pred = kmeans.fit_predict(X) pred
4.7 输出图像
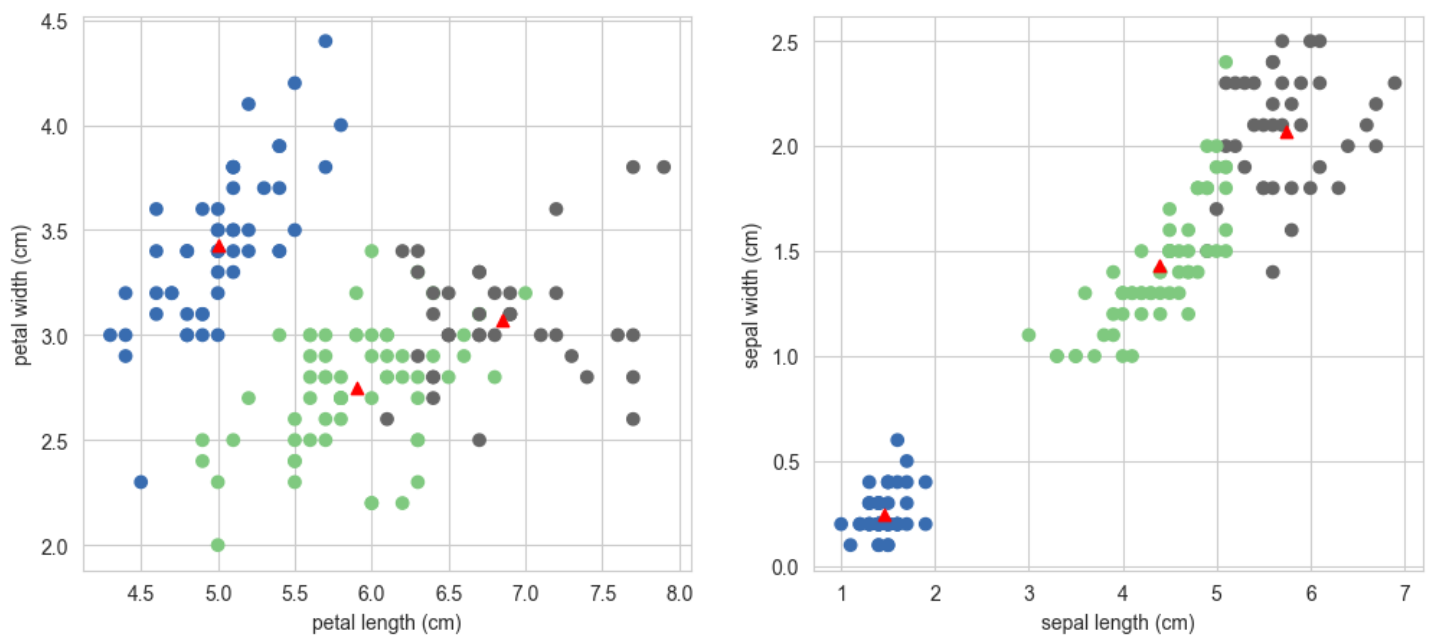
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 plt.figure(figsize=(12 ,5 )) plt.subplot(1 , 2 , 1 ) plt.scatter(X[:,0 ], X[:,1 ],c=pred, cmap=cm.Accent) plt.grid(True ) for center in kmeans.cluster_centers_: center = center[:2 ] plt.scatter(center[0 ],center[1 ],marker = '^' ,c = 'red' ) plt.xlabel("petal length (cm)" ) plt.ylabel("petal width (cm)" ) plt.subplot(1 , 2 , 2 ) plt.scatter(X[:,2 ], X[:,3 ], c=pred, cmap=cm.Accent) plt.grid(True ) for center in kmeans.cluster_centers_: center = center[2 :4 ] plt.scatter(center[0 ],center[1 ],marker = '^' ,c = 'red' ) plt.xlabel("sepal length (cm)" ) plt.ylabel("sepal width (cm)" ) plt.show()

.png)